Appearance
Prometheus 基础
Prometheus 在指标体系里的角色是:找到所有目标的 /metrics 接口,把指标抓回来,存进本地时序数据库,再用 PromQL 支持查询、看板和告警规则。主机、数据库、缓存、Web 服务、Kubernetes 组件——只要能暴露 Prometheus 格式的指标,就可以接进同一套体系里。
它不存日志,不存请求上下文,只存时间序列:指标名、标签、时间戳、数值。
一条时间序列的四要素
在 Prometheus 眼里,每条数据长这样:
text
up{job="node", instance="192.168.10.12:9100", env="lab"} 1| 部分 | 说明 | 例子 |
|---|---|---|
| 指标名 | 测量的是什么 | up——表示最近一次抓取是否成功 |
| 标签 | 这条数据来自哪里、什么环境 | job="node"、instance、env |
| 时间戳 | 数据在什么时间点产生的 | 由 Prometheus 抓取时记录 |
| 值 | 那个时间点的数字 | 1=成功,0=失败 |
up{job="node", instance="192.168.10.11:9100"} 和 up{job="node", instance="192.168.10.12:9100"} 是两条不同的序列——instance 标签不一样。标签是 Prometheus 很重要的设计,可以按任意维度聚合或筛选。但标签不是越多越好——每个标签值组合都产生新序列,标签值的变化种类(基数)太高会导致存储爆炸。
Pull 模型:Prometheus 主动去拉
Prometheus 默认是 Pull 模型——它主动去各个目标抓指标,不是等目标推过来。这和很多监控工具(Zabbix Agent 主动上报、Nightingale Categraf 推送)的路线不一样。
Pull 模型的一个好处是:Prometheus 的 Targets 页面能直接看到每个目标的最后一次抓取状态——成功还是失败、耗时多少、报了什么错。Prometheus 机器上执行 curl http://目标:端口/metrics 能直接验证网络和 exporter 是否正常。
但 Pull 模型也有不适用的场景。短生命周期任务(比如一个定时任务的备份脚本跑 3 秒就退出)不一定等得到 Prometheus 下一次抓取。针对这类场景,Prometheus 生态里有一个 Pushgateway 作为补充:短任务退出前把最后一次结果推到 Pushgateway,Prometheus 再从 Pushgateway 抓取。Pushgateway 是临时中转站,不是长期指标存储。
实验环境
三台 Rocky Linux 9.7,全部接入 Prometheus:
| 主机 | 角色 | 组件 |
|---|---|---|
192.168.10.11 mon01 | 监控节点 | Prometheus、Alertmanager、Grafana、Node Exporter、Nginx、Nginx Exporter |
192.168.10.12 db01 | 数据库节点 | Node Exporter、MariaDB、mysqld_exporter |
192.168.10.13 cache01 | 缓存节点 | Node Exporter、Redis、redis_exporter |
组件版本固定如下:
| 组件 | 版本 |
|---|---|
| Prometheus | 3.11.3 |
| Node Exporter | 1.11.1 |
| Alertmanager | 0.32.1 |
| mysqld_exporter | 0.19.0 |
| redis_exporter | 1.84.0 |
| nginx-prometheus-exporter | 1.5.1 |
| Grafana | 13.0.1+security-01 |
安装 Prometheus
Prometheus 用二进制包部署在 mon01。目录按运维习惯拆开:配置放 /etc/prometheus,数据放 /var/lib/prometheus,二进制放 /usr/local/bin。拆开的目的是备份、升级和排错时路径不会混在一起。
bash
# 创建运行用户——不给登录 shell,减少攻击面
useradd --system --no-create-home --shell /sbin/nologin prometheus
# 配置、数据和下载目录分开
mkdir -p /etc/prometheus/rules /var/lib/prometheus /opt/monitor/src
cd /opt/monitor/src
# 下载官方二进制包,生产环境还会校验 checksum
curl -fL -o prometheus-3.11.3.linux-amd64.tar.gz \
https://github.com/prometheus/prometheus/releases/download/v3.11.3/prometheus-3.11.3.linux-amd64.tar.gz
tar -xzf prometheus-3.11.3.linux-amd64.tar.gz
# install 同时设置权限,路径不包含版本号——升级只需替换二进制
install -m 0755 prometheus-3.11.3.linux-amd64/prometheus /usr/local/bin/prometheus
install -m 0755 prometheus-3.11.3.linux-amd64/promtool /usr/local/bin/promtool
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus基础配置文件 /etc/prometheus/prometheus.yml:
yaml
global:
scrape_interval: 15s # 每 15 秒去每个 target 抓一次
evaluation_interval: 15s # 每 15 秒计算一次告警规则
rule_files:
- /etc/prometheus/rules/*.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093 # Alertmanager 地址,用于接收 Prometheus 发送的告警
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 127.0.0.1:9090
labels:
env: lab
role: monitor启动前先检查配置有没有 YAML 语法错误或路径引用问题:
bash
promtool check config /etc/prometheus/prometheus.ymlsystemd unit 放在 /etc/systemd/system/prometheus.service:
ini
[Unit]
Description=Prometheus Monitoring Server
After=network-online.target alertmanager.service
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--storage.tsdb.retention.time=15d \
--web.listen-address=:9090 \
--web.enable-lifecycle
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target几个启动参数的含义:
| 参数 | 作用 |
|---|---|
--config.file | 主配置文件路径 |
--storage.tsdb.path | 时序数据存哪里 |
--storage.tsdb.retention.time=15d | 本地保留 15 天,过期自动删除 |
--web.listen-address=:9090 | 监听端口 |
--web.enable-lifecycle | 允许通过 HTTP API 热加载配置,不用重启服务 |
启动:
bash
systemctl daemon-reload
systemctl enable --now prometheus
# 确认 Prometheus 已启动并可以对外服务
curl -s http://127.0.0.1:9090/-/ready接入多类 Exporter
当前实验接入了五类 job:node(三台主机)、mysql(db01 上的 MySQL)、redis(cache01 上的 Redis)、nginx(mon01 上的 Nginx)、prometheus(自身监控)。每个 target 地址背后是一个 Exporter——部署方式见 Node Exporter 和 服务 Exporter。
yaml
scrape_configs:
- job_name: node
static_configs:
- targets:
- 192.168.10.11:9100
labels:
env: lab
role: monitor
hostname: mon01
- targets:
- 192.168.10.12:9100
labels:
env: lab
role: database
hostname: db01
- targets:
- 192.168.10.13:9100
labels:
env: lab
role: cache
hostname: cache01
- job_name: mysql
static_configs:
- targets:
- 192.168.10.12:9104
- job_name: redis
static_configs:
- targets:
- 192.168.10.13:9121
- job_name: nginx
static_configs:
- targets:
- 192.168.10.11:9113static_configs 适合实验和小规模环境——目标写死在配置里,改了就要重载配置。生产里目标经常变化(Pod 创建又销毁、机器上下线),更常用文件发现、Consul 服务发现、或 Kubernetes 的 ServiceMonitor 来自动发现新目标。
Targets 页面:每条抓取链路的体检窗口
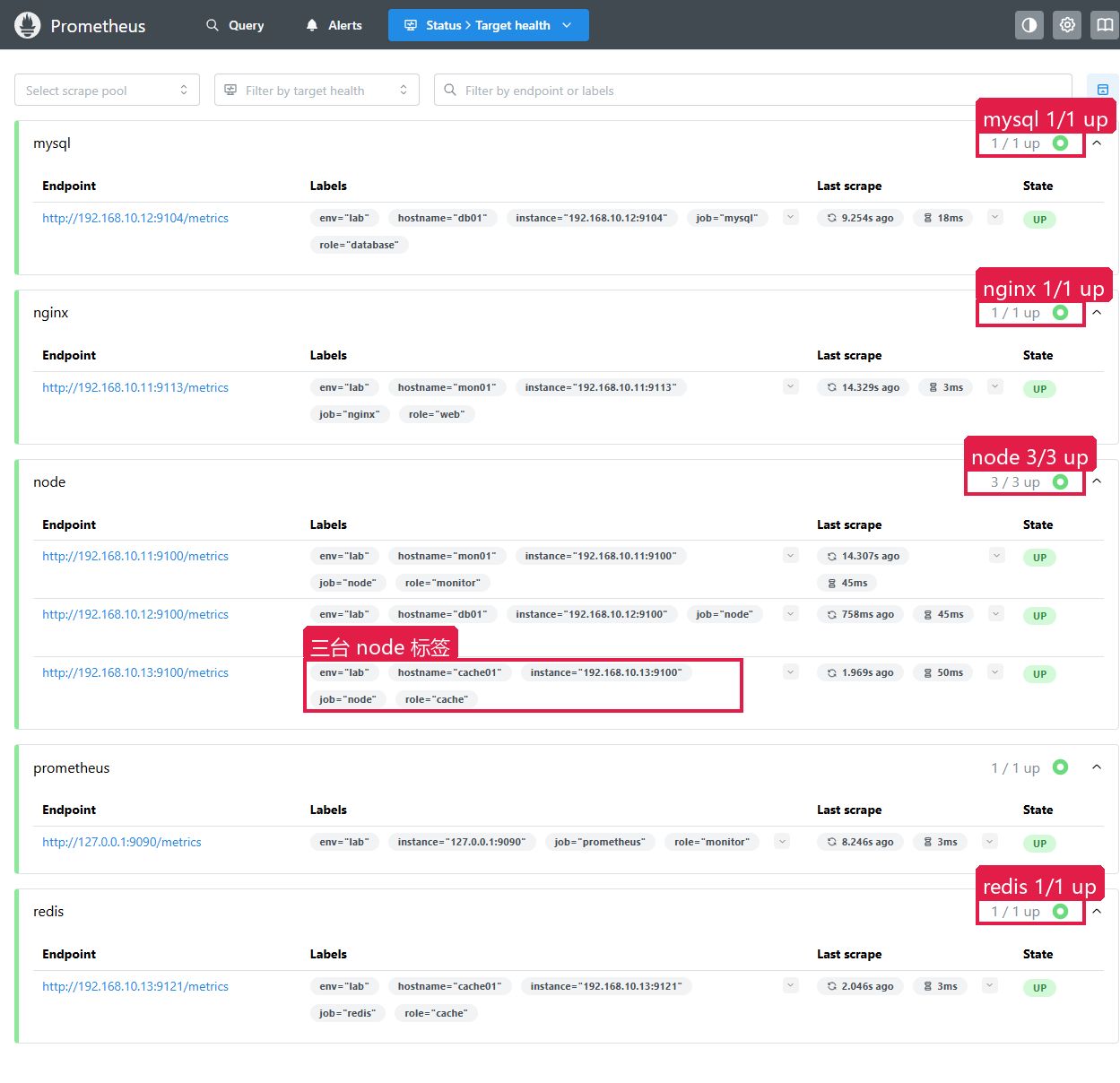
配置写好后,先看 Targets 页面确认 Prometheus 是不是能抓到每个目标。
页面路径:Status → Target health(中文:状态 → 目标健康状态)
操作步骤:
- 打开 Prometheus Web 页面(
http://192.168.10.11:9090) - 进入
Status → Target health - 通过
Select scrape pool下拉框过滤想看哪类 job,或在搜索框按 instance、hostname 筛选 - 展开对应采集池,看
Endpoint、Labels、Last scrape和State
每一列的含义:
| 列 | 含义 |
|---|---|
| Endpoint | Prometheus 实际抓取的地址 |
| Labels | 进入时间序列的标签,后续查询、告警都用这些标签 |
| Last scrape | 最近一次抓取距现在的时间和抓取耗时 |
| State | UP=抓取成功,DOWN=抓取失败 |
当前实验里 node 是 3 / 3 up,mysql、redis、nginx、prometheus 都是 1 / 1 up。
State=UP 只说明 Prometheus 到 Exporter 的 HTTP 抓取成功了。mysql_up=1 才说明 MySQL Exporter 能连上数据库。抓取链路和业务健康是两件事。
Target 是 DOWN 时,展开那一行能看到最后一个错误原因。常见的有:
| 错误信息 | 大概原因 |
|---|---|
connection refused | 目标端口上没有进程在监听 |
context deadline exceeded | 网络不通或目标响应太慢 |
no route to host | IP 不可达,路由问题 |
server returned HTTP status | 抓到了错误页面或需要认证 |
看到错误后,不要只在页面上猜。在 Prometheus 所在机器上直接 curl http://目标:端口/metrics,再登录目标机器看 exporter 服务和防火墙。一步一步验证链路。
第一次查询:用 up 验整条链路
这条查询用来确认"从指标进入 TSDB 到 PromQL 查出结果"这条链路是通的。
页面路径:Query(中文:查询)
操作步骤:
- 进入 Prometheus Web 的
Query页面 - 在表达式输入框填
sum by (job) (up) - 点击
Execute Table视图里看每个 job 的结果值
promql
sum by (job) (up)job 是采集任务名,sum by (job) 的意思是"按 job 分组求和"。结果里 node 返回值是 3(三台主机的 exporter 都是 UP),其余 job 返回 1。
命令行也可以用 curl 查同一条表达式——API 返回的数据和页面一样,适合脚本化验证和自动巡检:
bash
# -G 配合 --data-urlencode,避免 PromQL 里的括号和空格被 URL 转义影响
curl -sG \
--data-urlencode 'query=sum by (job) (up)' \
http://127.0.0.1:9090/api/v1/query启动和抓取常见问题
| 现象 | 常见原因 | 先看什么 |
|---|---|---|
| Prometheus 起不来 | YAML 缩进错误、规则文件语法错、端口被占用 | promtool check config、journalctl -u prometheus |
Target DOWN | exporter 没启动、端口不通、地址写错 | 在 Prometheus 机器上 curl http://target:端口/metrics |
Target UP 但查不到预期指标 | exporter 版本和权限、服务端实际状态 | 直接看 /metrics 原始输出有没有那个指标名 |
| 查询曲线断断续续 | target 抓取间歇性失败、机器重启、时间范围太短 | Targets 页面和 up 指标 |
| Prometheus 磁盘快速增长 | 抓取目标太多、标签基数高、保留时间太长 | 看 TSDB 状态和高基数指标 |
页面查询失败时,先看表达式有没有语法错误(语法错误会在页面上直接标红);查询结果为空但 Targets 正常时,通常是标签条件写太窄了,或者时间范围里没有样本。把表达式一步步退回最简单、只加一个标签条件,更容易定位是哪个条件筛掉了数据。