Appearance
Alertmanager
Prometheus 的 Alerts 页面能看到一条告警进入了 firing 状态。但 firing 只是"Prometheus 判定异常了",还没有真的发出去。Alertmanager 的工作就是接手这些告警,决定哪些合在一起发、哪些维持期间静默、哪些被更高级的告警抑制、最终走哪个渠道到谁手上。
Prometheus 发给 Alertmanager 的不是 PromQL 表达式,而是已经触发的具体告警实例——每一条都带着完整的 labels 和 annotations。Alertmanager 只认告警身上的标签,不关心 PromQL 长什么样。
当前实验部署
| 项 | 值 |
|---|---|
| 部署位置 | mon01(和 Prometheus 同一台) |
| 访问地址 | 192.168.10.11:9093 |
| 配置文件 | /etc/alertmanager/alertmanager.yml |
| 数据目录 | /var/lib/alertmanager |
| 实验用接收器 | lab-webhook(写到本地日志文件) |
| Webhook 日志路径 | /var/log/lab-alert-webhook.log |
安装
bash
mkdir -p /etc/alertmanager /var/lib/alertmanager /opt/monitor/src
cd /opt/monitor/src
curl -fL -o alertmanager-0.32.1.linux-amd64.tar.gz \
https://github.com/prometheus/alertmanager/releases/download/v0.32.1/alertmanager-0.32.1.linux-amd64.tar.gz
tar -xzf alertmanager-0.32.1.linux-amd64.tar.gz
# 固定路径,升级不改 unit
install -m 0755 alertmanager-0.32.1.linux-amd64/alertmanager /usr/local/bin/alertmanager
install -m 0755 alertmanager-0.32.1.linux-amd64/amtool /usr/local/bin/amtool
chown -R prometheus:prometheus /etc/alertmanager /var/lib/alertmanagersystemd unit:
ini
[Unit]
Description=Prometheus Alertmanager
After=network-online.target
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yml \
--storage.path=/var/lib/alertmanager \
--web.listen-address=:9093
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.targetbash
# 检查配置语法
amtool check-config /etc/alertmanager/alertmanager.yml
systemctl daemon-reload
systemctl enable --now alertmanager
# 确认 ready
curl -s http://127.0.0.1:9093/-/ready路由和接收器是怎么配合的
Alertmanager 的核心概念只有四个:route(路由)、receiver(接收器)、group(分组)、silence(静默)。当前实验配置了一个最简版本:
yaml
global:
resolve_timeout: 5m
route:
receiver: lab-webhook
group_by:
- alertname
- instance
group_wait: 10s
group_interval: 30s
repeat_interval: 5m
receivers:
- name: lab-webhook
webhook_configs:
- url: http://127.0.0.1:5001/alert
send_resolved: true每个字段的作用:
| 字段 | 含义 | 当前设了什么 |
|---|---|---|
receiver | 默认由哪个接收器处理 | lab-webhook |
group_by | 按哪些标签把告警合并成一组 | 同 alertname + 同 instance 的告警合并 |
group_wait | 新分组第一次发之前等多久 | 等 10s——给同组的其他告警留时间赶到 |
group_interval | 同组后续告警到来后,间隔多久才能再发 | 30s——不会每来一单告警都立刻再发 |
repeat_interval | 告警一直没恢复的话,多久重发提醒一次 | 5m |
send_resolved | 告警恢复了要不要也发一条 | true——知道什么时候恢复很重要 |
分组的作用:一台机器的网络断了,同时触发 NodeExporterDown、几个服务 Exporter DOWN、磁盘指标缺失——如果不分组,值班的人会接连收到好几条独立通知。group_by: ['alertname', 'instance'] 的意思是同名告警、同一实例合并发送,把一轮告警风暴拢成一条通知。
group_wait 和 group_interval 的操作流程:第一个告警到达 → 等 10s(group_wait)→ 发第一组通知。30 秒之内又有同一组的新告警到达 → 等 30s(group_interval)→ 发第二组。这种设计避免了告警密集爆发时通知渠道被打爆。
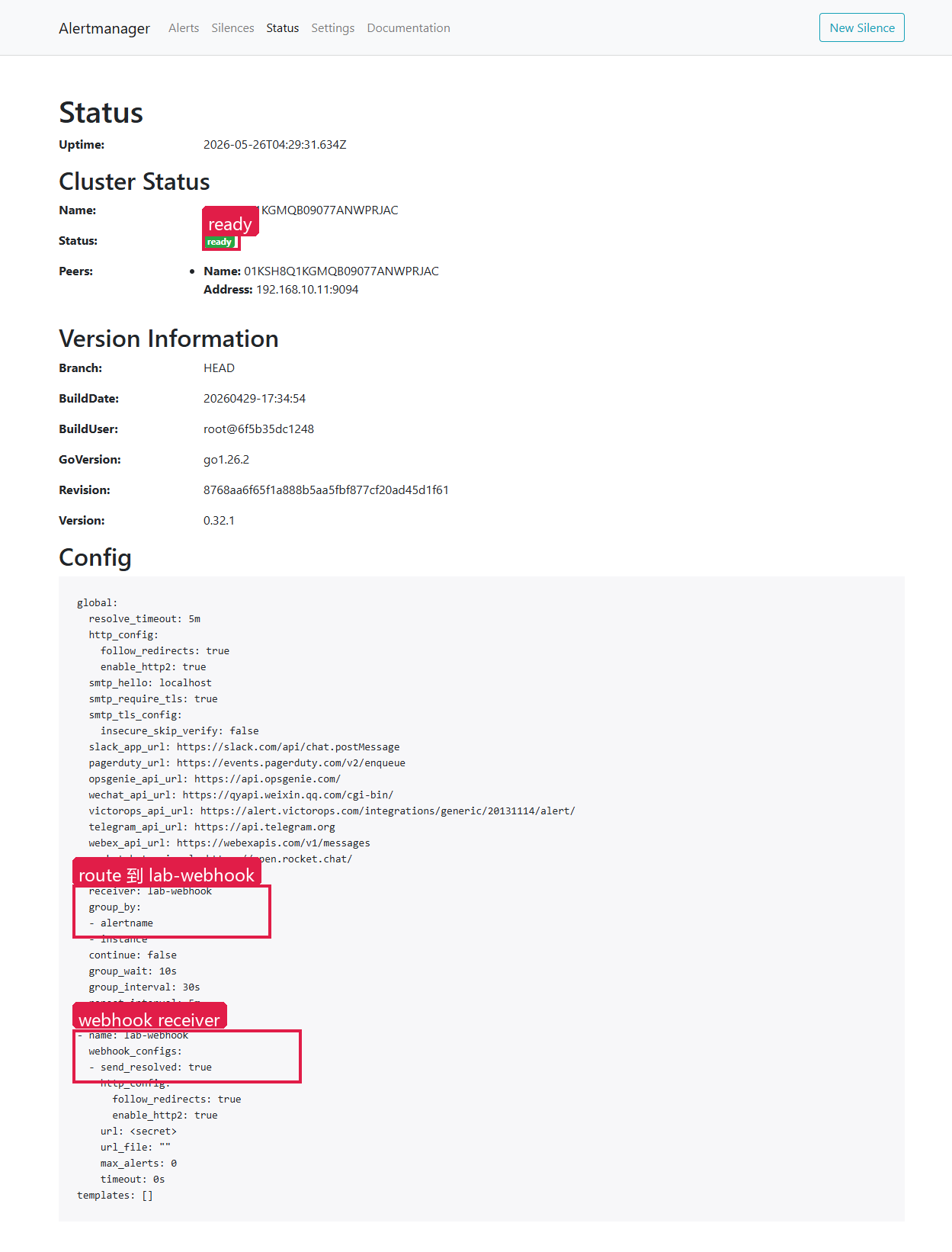
Alertmanager Status 页面能确认当前加载的配置。页面路径:Status(中文:状态)
操作步骤:
- 打开 Alertmanager Web 页面
- 进入
Status - 确认
Cluster Status是否为ready - 在
Config区域核对route.receiver、group_by、repeat_interval和receivers
Prometheus 和 Alertmanager 的关系
Prometheus 需要知道 Alertmanager 在哪——在 Prometheus 主配置里指定:
yaml
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093两边配置都改完、分别检查后,重载 Prometheus:
bash
promtool check config /etc/prometheus/prometheus.yml
amtool check-config /etc/alertmanager/alertmanager.yml
curl -X POST http://127.0.0.1:9090/-/reload验证链路:Prometheus Alerts 页面有 firing 告警,Alertmanager Alerts 页面也能看到同一条——Prometheus 到 Alertmanager 这头就是通的。
检查实验告警
前面定义的 LabNodeExporterAlwaysFiring 只要 cache01 正常就会一直 firing,很适合用来验证整条通知链路。
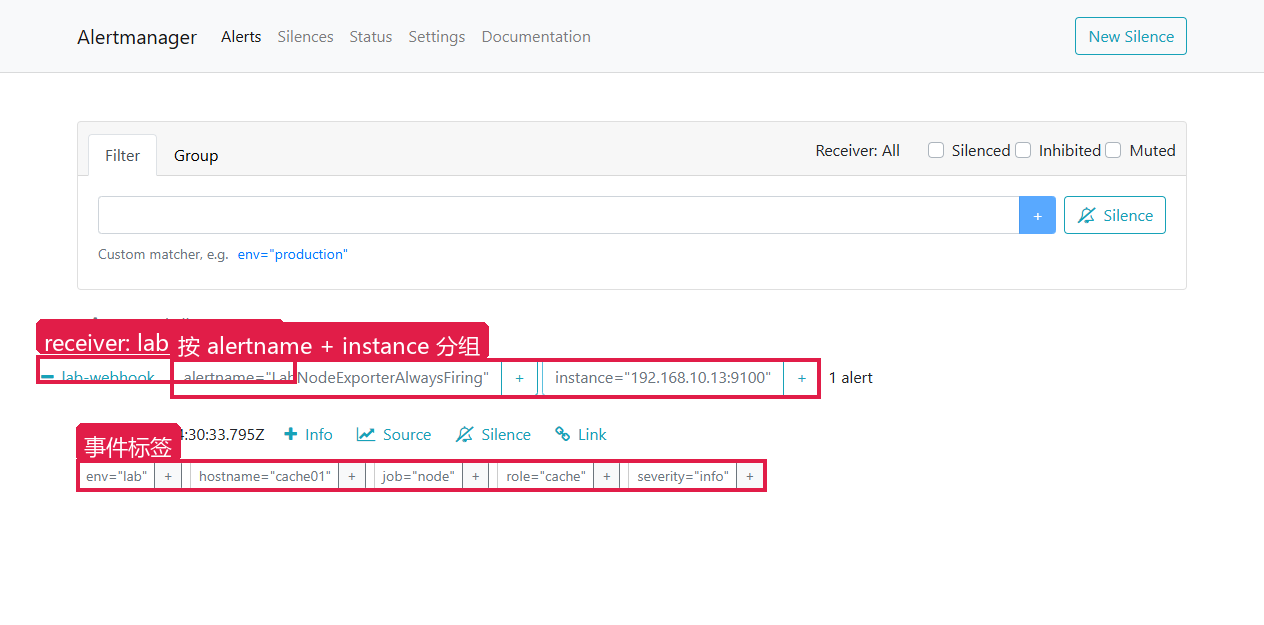
Alertmanager Alerts 页面:Alerts(中文:告警)
操作步骤:
- 打开 Alertmanager Web 的
Alerts页面 - 按
alertname="LabNodeExporterAlwaysFiring"过滤 - 看 Receiver 是不是
lab-webhook - 展开告警,看 labels(
env、hostname、job、severity等)
Receiver 侧检查 Webhook 日志:
bash
# 看最近收到的告警内容
tail -n 40 /var/log/lab-alert-webhook.log
# 搜索有没有发给 lab-webhook 的告警记录
grep -E 'LabNodeExporterAlwaysFiring|cache01|lab-webhook' /var/log/lab-alert-webhook.logWebhook 日志里有告警记录,说明"Prometheus 规则 → Alertmanager → receiver 发送"这一串全通了。真实环境里换成企业微信、飞书、钉钉、邮件等真实渠道时,本质上只是把 receiver 从实验 Webhook 换成对应的通知媒介。
三个核心操作:分组、静默、抑制
| 功能 | 做什么 | 什么场景用 |
|---|---|---|
| 分组 | 多条相关告警合成一条发 | 同一实例多个告警一起出现 |
| 静默 | 指定时间内屏蔽匹配的告警 | 发布窗口、计划的机器维护 |
| 抑制 | 高级别告警触发时自动屏蔽低级别 | 节点宕机→该节点上其他告警都是派生,不用再发一遍 |
静默要特别注意 matcher 的匹配条件——要和告警上的实际 labels 严格一致。比如告警上的 instance 是 192.168.10.13:9100,静默条件写 instance=192.168.10.13(少了端口),就不会匹配。维护窗口结束后仍然没收到告警,第一步就是查 silence matcher 是否和告警 labels 对得上。
抑制规则适合清理派生告警。节点宕机时,该机器上的 Node Exporter、MySQL Exporter、Redis Exporter 可能同时 DOWN——这其实是同一个根因。用抑制让高级别告警屏蔽同实例的低级别告警,通知一次就够了。
排查常见故障
| 现象 | 可能原因 | 先查什么 |
|---|---|---|
| Prometheus 有 firing,Alertmanager 没有 | 地址配错、网络不通、Alertmanager 没启动 | alerting.alertmanagers 配置、journalctl -u alertmanager |
| Alertmanager 有告警,但 Webhook 没日志 | receiver URL 写错、路由没命中、Webhook 服务没起 | receiver 配置、curl Webhook URL |
| 通知特别频繁 | repeat_interval 太短,或分组太细了 | 检查 group_by 和 repeat_interval |
| 多条相似告警分开来了 | group_by 没用好 | 确认按 alertname+instance 分组合适吗 |
| 静默不生效 | matcher 和真实 labels 不匹配 | 比对静默条件里的标签值和告警上的标签值 |
| 恢复通知没收到 | send_resolved 没开 | 检查 receiver 配置 |
排查时有固定的三处交叉验证:Prometheus Alerts 页面 → Alertmanager Alerts 页面 → receiver 日志。这三点串起来基本能定位是规则没触发、触发了没交给 Alertmanager,还是交给 Alertmanager 了但通知没发出。