Appearance
Nightingale基础
Nightingale 通常简称 N9E,更像一套围绕指标、告警、通知和组织权限做整合的监控平台。它本身不是单纯的时序数据库,也不是只负责画图的看板工具;指标存储可以交给 VictoriaMetrics、Prometheus、Mimir 这类 Prometheus 兼容后端,采集端可以用 Categraf,N9E 负责把查询、告警、通知、人员组织和平台操作串起来。
我个人更愿意把 N9E 放在“监控平台入口”这个位置。小环境直接 Prometheus + Grafana + Alertmanager 就够用;机器和团队多起来以后,告警规则、通知媒介、业务组权限、采集对象、值班处理都集中到 N9E 里会更顺。
一、N9E 在监控体系里的位置
可观测性里常见的指标链路是:采集端拿指标,写入时序库,平台做查询、看板和告警。N9E 站在平台层,它可以接收 Categraf 上报,也可以配置 Prometheus Like 数据源去查后端时序库。
几个角色要分清:
| 组件 | 作用 | 运维时关注点 |
|---|---|---|
| N9E Server | Web 控制台、API、告警规则、通知、组织权限 | 版本、配置、数据库连接、登录入口 |
| Categraf | 主机、中间件、应用指标采集端 | 采集插件、主机标识、上报地址、服务状态 |
| VictoriaMetrics | 存储 Prometheus 格式的时序数据 | 数据目录、保留周期、查询性能、磁盘容量 |
| MySQL | 保存 N9E 平台数据 | 备份、账号权限、表结构升级 |
| Redis | 平台缓存和部分运行时状态 | 连接状态、内存、持久化策略 |
| 告警引擎 | 计算告警规则并生成事件 | 规则执行、集群状态、通知链路 |
N9E 和 Grafana 的重叠点在查询和看板,但侧重点不一样。Grafana 的图表生态很强,适合统一展示多类数据源;N9E 更偏监控平台管理,告警规则、通知媒介、业务组、采集对象这些东西更靠前。生产里两者也可以并存,N9E 管告警和监控对象,Grafana 保留复杂看板。
二、实验环境
当前实验固定使用 N9E 8.5.1。GitHub 和镜像仓库里已经能看到 9.0.0-beta.1,直接用 latest 容易把实验带到新大版本,配置和界面都有变化。
| 主机 | 角色 | 说明 |
|---|---|---|
192.168.10.11 | N9E、VictoriaMetrics、MySQL、Redis、Categraf | 监控平台入口 |
192.168.10.12 | Categraf | 被监控节点 |
192.168.10.13 | Categraf | 被监控节点 |
实验版本:
| 组件 | 版本 |
|---|---|
| Nightingale | flashcatcloud/nightingale:8.5.1 |
| Categraf | flashcatcloud/categraf:v0.5.7 / categraf-v0.5.7-linux-amd64 |
| VictoriaMetrics | victoriametrics/victoria-metrics:v1.79.12 |
| MySQL | mysql:8 |
| Redis | redis:6.2 |
国内环境拉镜像时经常碰到网络抖动或镜像层缺失。当前实验 Docker daemon 配了 1ms 镜像源,但 VictoriaMetrics 新版本镜像层出现过 404,最后固定回官方 Compose 里原本的 v1.79.12。这类实验环境里,版本可复现比追最新更重要。
三、服务端部署结构
服务端放在 192.168.10.11,目录是:
text
/opt/n9e-lab/
├── compose-bridge/
│ ├── docker-compose.yaml
│ ├── etc-categraf/
│ ├── etc-mysql/
│ └── etc-nightingale/
└── initsql/Compose 里核心服务如下:
yaml
services:
# MySQL 保存 N9E 的用户、角色、规则、通知等平台数据
mysql:
image: "mysql:8"
environment:
MYSQL_ROOT_PASSWORD: 1234
volumes:
- ./mysqldata:/var/lib/mysql/
- ../initsql:/docker-entrypoint-initdb.d/
# Redis 用于平台缓存、登录态和部分运行时状态
redis:
image: "redis:6.2"
# VictoriaMetrics 负责存储 Prometheus 格式的时序数据
victoriametrics:
image: victoriametrics/victoria-metrics:v1.79.12
ports:
- "8428:8428"
# N9E 提供 Web 控制台、API、告警和 remote_write 接收入口
nightingale:
image: flashcatcloud/nightingale:8.5.1
ports:
- "17000:17000"
- "20090:20090"
depends_on:
- mysql
- redis
- victoriametrics17000 是 Web 和 API 入口,20090 是 Ibex/RPC 相关端口。Categraf 的心跳和指标写入都走 17000,远程命令这类能力会用到 20090。
启动后检查容器:
bash
# 进入 N9E 实验目录
cd /opt/n9e-lab/compose-bridge
# 查看 N9E、MySQL、Redis、VictoriaMetrics、Categraf 状态
docker compose ps
# 看 N9E 启动日志,默认账号会出现在初始化日志里
docker compose logs --tail=80 nightingale日志里能看到默认入口和账号:
text
please view n9e at http://172.18.0.5:17000
username/password: root/root.2020
http server listening on: 0.0.0.0:17000浏览器访问:
text
http://192.168.10.11:17000这张登录截图只用于确认 Web 控制台入口已经可访问,不承担平台操作教程。后续平台配置以数据源、Dashboard、告警规则和事件页面为主。
实验环境默认账号是 root/root.2020。真实环境里默认口令通常在初始化阶段就改掉;N9E 里能看到数据源、告警规则、通知配置和部分组织信息,暴露到公网风险很高。
四、N9E 配置里最关键的几段
N9E 服务端配置在 etc-nightingale/config.toml。基础环境里重点看数据库、Redis、remote write 写入后端和 RPC 端口。
toml
[DB]
# N9E 平台数据存到 MySQL,容器网络里直接访问 mysql:3306
DSN = "root:1234@tcp(mysql:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local"
DBType = "mysql"
[Redis]
# Redis 用于缓存和运行时状态
Address = "redis:6379"
RedisType = "standalone"
[[Pushgw.Writers]]
# Categraf 写到 N9E 后,N9E 再把指标写入 VictoriaMetrics
Url = "http://victoriametrics:8428/api/v1/write"
[Ibex]
# Categraf 远程任务相关 RPC 入口
Enable = true
RPCListen = "0.0.0.0:20090"Pushgw.Writers 是很容易忽略的一段。Categraf 并不是直接写 VictoriaMetrics,而是写到 N9E 的 /prometheus/v1/write,N9E 再转发到后端时序库。这样平台能在中间处理监控对象、标签改写和部分管理逻辑。
五、Categraf 采集端
Categraf 是 N9E 体系里常用的采集端。它和 Node Exporter 有些像,都会采主机指标;区别是 Categraf 插件更多,也能直接把数据写到 N9E。
192.168.10.12 和 192.168.10.13 使用二进制方式运行 Categraf,systemd 托管:
ini
[Unit]
Description=Categraf Agent
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
# 指向统一的配置目录,便于后续增删 input 插件
ExecStart=/usr/local/bin/categraf --configs /etc/categraf
Restart=always
RestartSec=5
# 采集端打开文件和连接较多时,默认限制可能偏小
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target采集端配置重点是主机标识和上报地址:
toml
[global]
# 主机标识会进入 ident 标签,排查和告警都靠它区分机器
hostname = "node12"
omit_hostname = false
# 基础采集间隔,实验环境 15 秒够用
interval = 15
providers = ["local"]
[global.labels]
# 稳定维度适合做全局标签
env = "lab"
region = "local"
[[writers]]
# 指标写到 N9E,再由 N9E 转写到 VictoriaMetrics
url = "http://192.168.10.11:17000/prometheus/v1/write"
timeout = 5000
[heartbeat]
# 心跳用于平台识别采集端在线状态
enable = true
url = "http://192.168.10.11:17000/v1/n9e/heartbeat"
interval = 10
[ibex]
# RPC 地址用于远程任务能力
enable = true
servers = ["192.168.10.11:20090"]我这次实际踩到的是 hostname。如果主机标识没有设置好,两台机器上报出来可能没有 ident,查询时就像混在一条时间序列里。主机监控里 ident、instance、env、region 这些标签要稳定,后面告警通知才知道是哪台机器出问题。
检查 Categraf 状态:
bash
# 查看采集端服务是否运行
systemctl status categraf --no-pager
# 看最近日志,确认 input 插件启动、heartbeat 正常
journalctl -u categraf -n 80 --no-pager六、数据源
N9E 页面查询指标前,需要配置数据源。当前实验里新增的是 Prometheus Like 数据源,名称为 VictoriaMetrics,查询地址指向容器网络里的 VictoriaMetrics:
text
http://victoriametrics:8428Remote Write 地址:
text
http://victoriametrics:8428/api/v1/write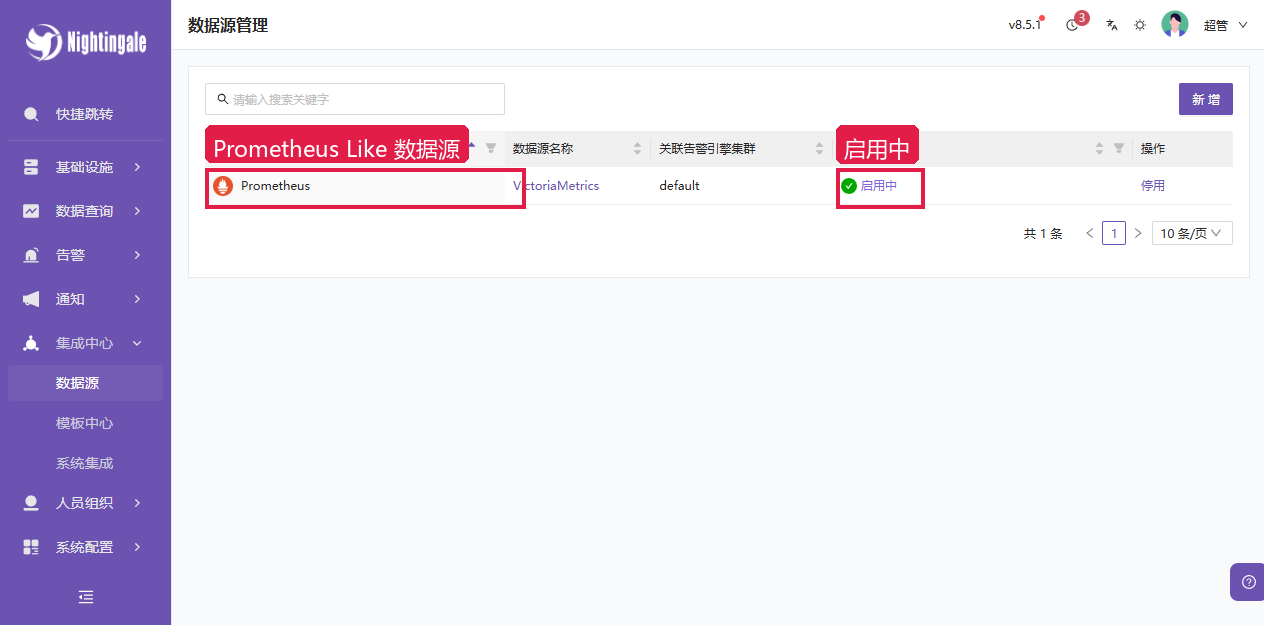
页面里“Prometheus Like”这个名字说明它按 Prometheus 查询协议工作,不代表后端一定是原生 Prometheus。VictoriaMetrics、Mimir、Thanos Query 这类兼容 PromQL 的后端,也可以作为 Prometheus Like 数据源接进来。
如果页面查询一直是“暂无数据”,但后端时序库里有数据,常见原因是数据源没配、当前页面没选数据源、URL 写成了宿主机不可达地址,或者查询时间范围不对。
七、验证指标链路
直接查 VictoriaMetrics 可以确认写入是否正常:
bash
# 查看当前已经出现的主机标识
curl -sS 'http://127.0.0.1:8428/api/v1/label/ident/values'
# 查询 CPU 空闲率,确认 node12 / node13 都有数据
curl -sS -G \
--data-urlencode 'query=cpu_usage_idle{cpu="cpu-total"}' \
http://127.0.0.1:8428/api/v1/query当前实验返回的主机标识:
json
{
"status": "success",
"data": ["categraf01", "node12", "node13"]
}页面里查询同一条表达式:
数据查询 -> 指标 (英文含义:Data query -> Metrics)
操作步骤:
- 进入
数据查询 -> 指标。 - 数据源选择
VictoriaMetrics。 - 输入
cpu_usage_idle{cpu="cpu-total"}。 - 执行查询,确认结果里有
node12、node13和categraf01。
promql
cpu_usage_idle{cpu="cpu-total"}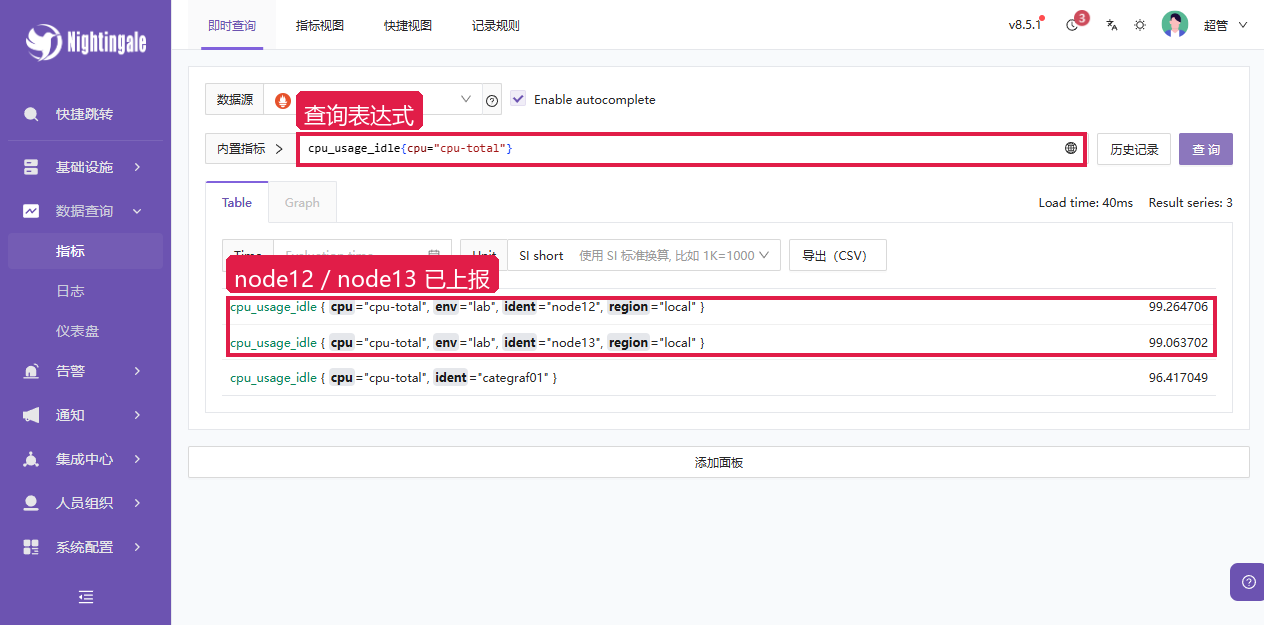
这张图能看到 node12、node13 和本机容器里的 categraf01。基础链路到这里才算打通:采集端运行、指标写入 N9E、N9E 转写到 VictoriaMetrics、页面通过数据源查到结果。
八、告警和通知的基本对象
N9E 的告警不是只写一条 PromQL。它还要和业务组、数据源、告警引擎、通知规则、通知媒介关联起来。
| 对象 | 作用 |
|---|---|
| 业务组 | 组织规则、人员、权限和告警归属 |
| 数据源 | 告警规则查询哪个时序库 |
| 告警规则 | PromQL、阈值、持续时间、标签和注释 |
| 告警引擎 | 定时执行规则并生成告警事件 |
| 告警事件 | 当前触发、恢复、认领、屏蔽等状态 |
| 通知媒介 | 邮件、Webhook、飞书、钉钉等发送方式 |
| 通知规则 | 哪些告警发给哪些人或哪些群 |
一条主机 CPU 告警大概会长这样:
promql
100 - cpu_usage_idle{cpu="cpu-total"} > 85告警规则里通常要保留这些标签:
| 标签 | 用途 |
|---|---|
ident | 哪台机器 |
env | 哪个环境 |
region | 哪个区域 |
severity | 告警级别 |
team | 归属团队 |
告警内容写得太“漂亮”没用,收到通知时能直接知道机器、环境、指标、当前值、持续时间和处理入口更重要。出现主机负载飙高时,通知里只有“CPU 高”四个字,值班的人还要重新进平台查一遍。
九、和 Prometheus 体系的关系
N9E 并没有把 Prometheus 体系推翻,它更多是把 Prometheus 生态里的几块重新组合:
| Prometheus 体系 | N9E 体系里的对应关系 |
|---|---|
| Exporter | Categraf 或各种 exporter |
| Prometheus remote_write | Categraf 写 N9E,N9E 写后端时序库 |
| PromQL | N9E 页面查询和告警规则仍然使用 PromQL |
| Alertmanager | N9E 自己有告警事件和通知能力 |
| Grafana Dashboard | N9E 也有仪表盘,但复杂看板可继续用 Grafana |
如果团队已经有一套 Prometheus + Grafana + Alertmanager,接 N9E 时不用一次性全部替换。比较稳的方式是让 N9E 接现有时序库或远端存储,再逐步迁告警规则和通知规则。线上最怕的是监控迁移时新旧平台口径不一致,告警漏发比页面不好看严重得多。
十、常见排查入口
N9E 基础问题可以按链路拆:
| 现象 | 检查点 |
|---|---|
| 页面打不开 | 17000 端口、容器状态、N9E 日志 |
| 登录失败 | 默认账号、MySQL 初始化、JWT/Redis 连接 |
| 页面查询无数据 | 数据源 URL、VictoriaMetrics 是否有数据、时间范围 |
| 采集端不上报 | Categraf 服务、writer URL、网络、N9E /prometheus/v1/write |
| 平台看不到主机 | heartbeat URL、ident/hostname、Categraf 日志 |
| 告警不触发 | 数据源、PromQL、告警引擎、规则持续时间 |
| 通知不发送 | 通知媒介、通知规则、用户联系方式、Webhook 连通性 |
几个常用检查命令:
bash
# N9E 服务端容器状态
cd /opt/n9e-lab/compose-bridge
docker compose ps
# N9E 页面入口
curl -I http://127.0.0.1:17000
# VictoriaMetrics 是否有 Categraf 上报的指标
curl -sS 'http://127.0.0.1:8428/api/v1/label/__name__/values' | head
# 被监控节点上的 Categraf 状态
systemctl is-active categraf
journalctl -u categraf -n 50 --no-pager我会把 N9E 的平台数据和部署文件都纳入备份:docker-compose.yaml、etc-nightingale/config.toml、etc-categraf/、MySQL 数据和告警通知配置。时序数据是否备份要看保留需求;平台配置和告警规则丢了,恢复成本通常更高。