Appearance
Grafana 指标看板
Grafana 在指标体系里负责连接数据源、查询数据和展示看板。它自己不去抓 Exporter,也不存指标——指标在 Prometheus 的 TSDB 里,Grafana 通过配置好的 Prometheus 数据源执行 PromQL 查询,再把结果用 Time series、Stat、Table 等面板呈现出来。
排查 Grafana 看板上没数据时,按这个顺序往下查通常效率更高:面板的 PromQL 和时间范围 → Grafana 数据源的 URL 和 Save & test → Prometheus Query 页面执行同一条 PromQL → Prometheus Targets 看 exporter 是否 UP → exporter 到真实服务的连通性。链路上任何一层断,Grafana 页面都没数据。
Grafana 和 Prometheus 都跑在 mon01 上。Grafana 数据源里填的 http://127.0.0.1:9090 是 Grafana 服务端去访问 Prometheus 的地址,不是浏览器本机访问 Prometheus 的地址。
安装 Grafana
版本固定为 13.0.1+security-01,通过 Yum 仓库安装:
bash
# 实验环境临时关闭 gpgcheck,生产更适合导入并校验 GPG key
cat >/etc/yum.repos.d/grafana.repo <<'EOF'
[grafana]
name=grafana
baseurl=https://rpm.grafana.com
repo_gpgcheck=0
enabled=1
gpgcheck=0
EOF
dnf install -y grafana
systemctl enable --now grafana-server
systemctl is-active grafana-serverGrafana 监听在 3000 端口,初始账号 admin/admin。浏览器访问 http://192.168.10.11:3000。
接入 Prometheus 数据源
实验用 provisioning 文件固化数据源配置,路径是 /etc/grafana/provisioning/datasources/prometheus.yml:
yaml
apiVersion: 1
datasources:
- uid: Prometheus
name: Prometheus
type: prometheus
access: proxy # 浏览器请求 Grafana,Grafana 后端去查 Prometheus
url: http://127.0.0.1:9090
isDefault: true
editable: true手工创建数据源时,页面路径:Connections → Data sources → Add data source → Prometheus(中文:连接 → 数据源 → 添加数据源 → Prometheus)
操作步骤:
- 进入
Connections → Data sources,点击Add data source - 选择
Prometheus - 填写数据源名称、Prometheus server URL、认证方式和 Scrape interval
- 点击
Save & test
关键字段:
| 字段 | 值 | 说明 |
|---|---|---|
| Name | Prometheus | 数据源名称,Dashboard 导入时用来映射 |
| Default | enabled | 作为默认数据源 |
| Prometheus server URL | http://127.0.0.1:9090 | Grafana 服务端访问 Prometheus 的地址 |
| Authentication | No Authentication | 实验环境 Prometheus 未开启认证 |
| Scrape interval | 15s | 和 Prometheus 抓取间隔一致 |
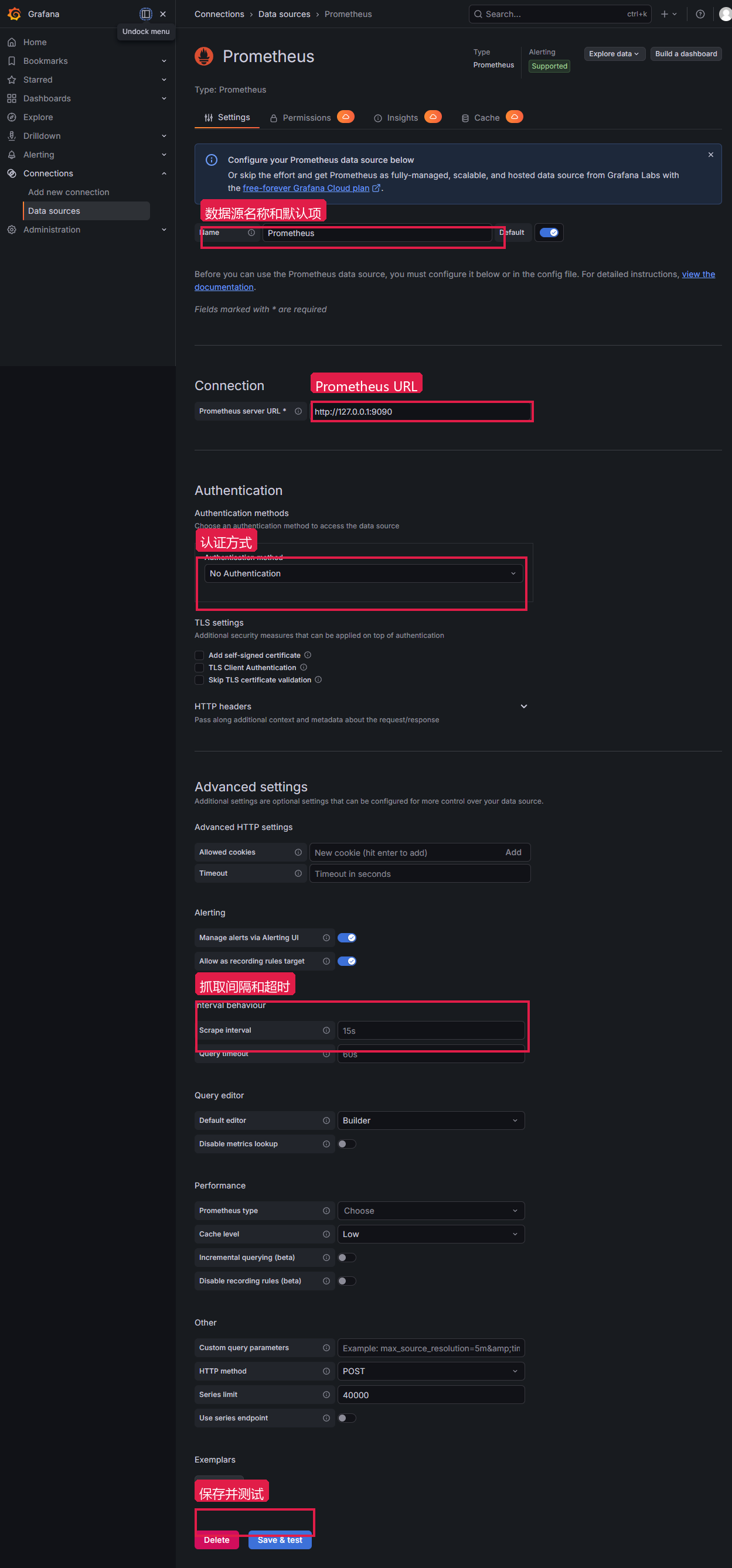
保存后进入 Explore(中文:探索)选 Prometheus 数据源,执行 sum by (job) (up) 有结果,说明数据源配置成功。
Save & test 失败时,在 mon01 上确认:
bash
# Grafana 服务端能否访问到 Prometheus
curl -s http://127.0.0.1:9090/-/ready
# 通过 Grafana API 看当前数据源列表
curl -s -u admin:admin http://127.0.0.1:3000/api/datasources浏览器能访问 http://192.168.10.11:9090 不代表 http://127.0.0.1:9090 一定能通——两者网络视角完全不同。
导入 Linux 节点大屏
实验 Dashboard 文件 grafana-linux-node-overview-lab.json 包含几个基础面板:
| 面板 | 类型 | 用到的 PromQL |
|---|---|---|
| UP 主机数 | Stat | sum(up{job="node"}) |
| CPU 使用率 | Time series | 按 instance 聚合的 idle CPU 反算 |
| Node Exporter 状态 | Table | up{job="node"} 按 hostname 展示 |
| 内存使用率 | Time series | MemAvailable / MemTotal |
导入路径:Dashboards → New → Import(中文:仪表盘 → 新建 → 导入)
操作步骤:
- 进入
Dashboards,点击New,选择Import - 上传或粘贴 Dashboard JSON
- 在
DS_PROMETHEUS下拉框选当前 Grafana 里的Prometheus数据源 - 点击
Import
| 字段 | 值 | 说明 |
|---|---|---|
| Name | Linux Node Overview Lab | 导入后的看板名称 |
| Folder | Dashboards | 看板保存目录 |
| DS_PROMETHEUS | Prometheus | 把 JSON 模板里的数据源变量映射到真实数据源 |
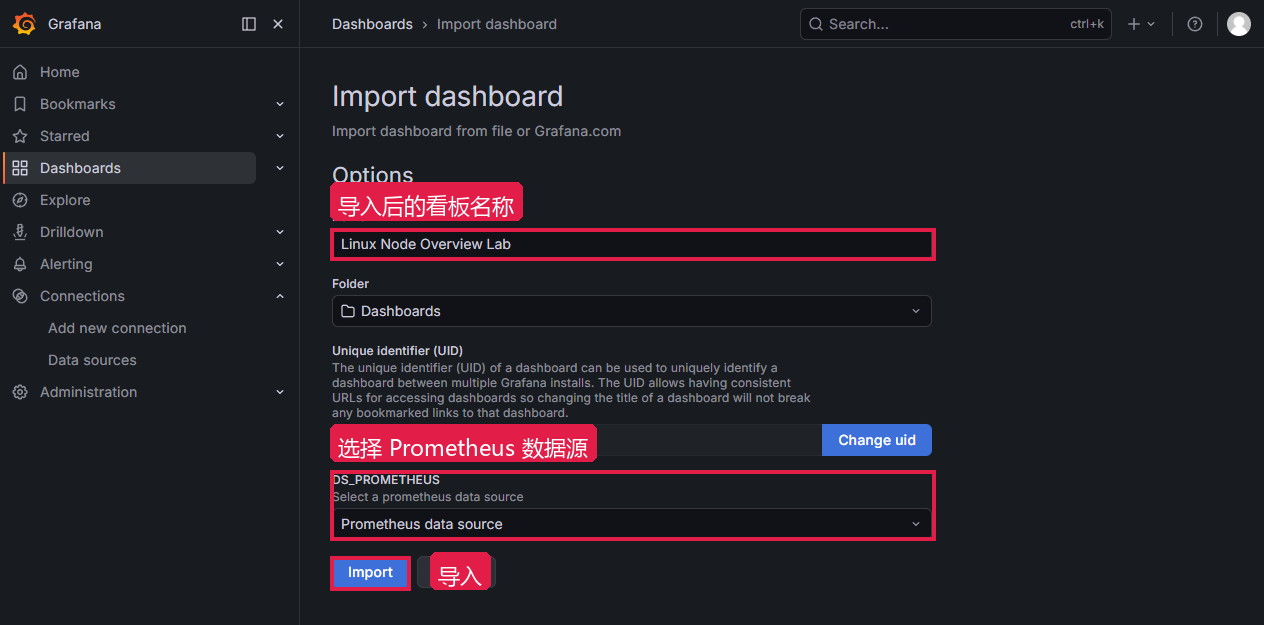
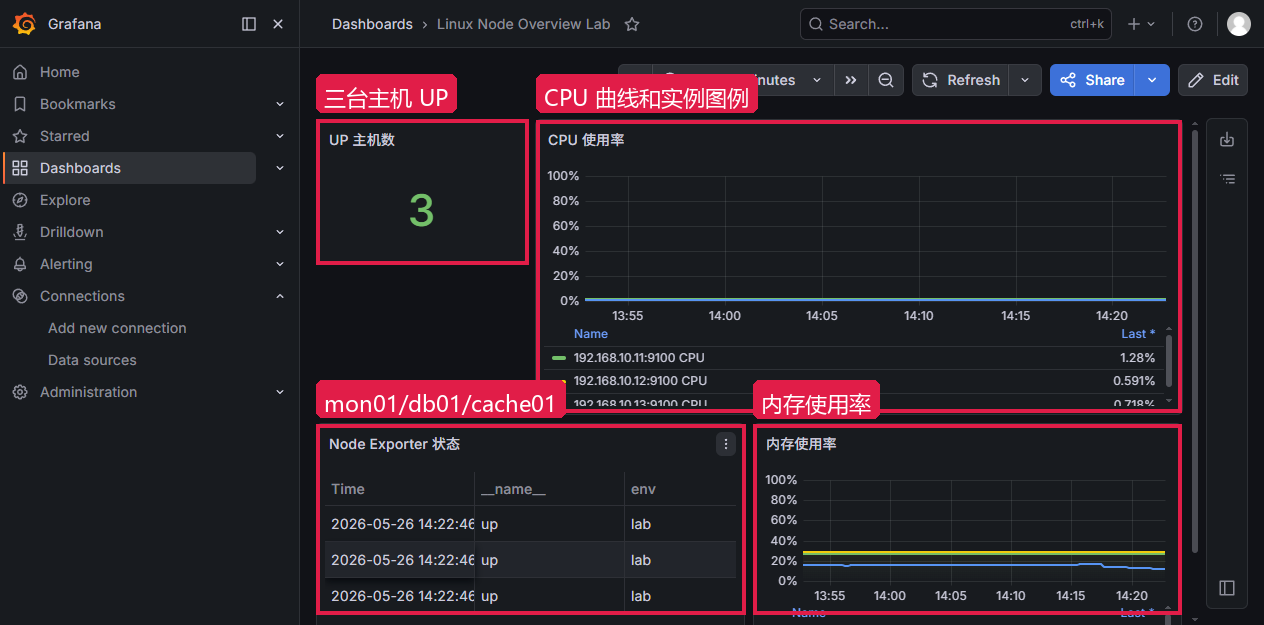
导入后进入看板,时间范围选最近 30 分钟。UP 主机数显示 3,CPU 和内存面板有 mon01、db01、cache01 的数据,说明数据源映射和 PromQL 都能正常工作。
面板 PromQL 配置
排查或修改看板时,经常要打开面板编辑器确认 PromQL、Legend 和面板配置。以 CPU 面板为例,编辑路径:Dashboards → Linux Node Overview Lab → CPU 使用率 → Panel menu → Edit(中文:仪表盘 → Linux Node Overview Lab → CPU 使用率 → 面板菜单 → 编辑)
操作步骤:
- 打开
Linux Node Overview Lab,CPU 面板标题处打开面板菜单 - 点击
Edit进入面板编辑器 - 在
Queries区域确认数据源是Prometheus,切到Code模式 - 右侧面板配置里确认标题、单位(Percent)和图例
| 字段 | 值 | 说明 |
|---|---|---|
| Visualization | Time series | CPU 合适看趋势 |
| Data source | Prometheus | 查询 Prometheus |
| Query | CPU 使用率 PromQL | 按 instance 聚合 |
| Legend | CPU | 图例保留实例地址 |
| Unit | Percent | 按百分比展示 |
CPU 面板使用的表达式:
promql
100 - (
avg by (instance) (
rate(node_cpu_seconds_total{job="node",mode="idle"}[5m])
) * 100
)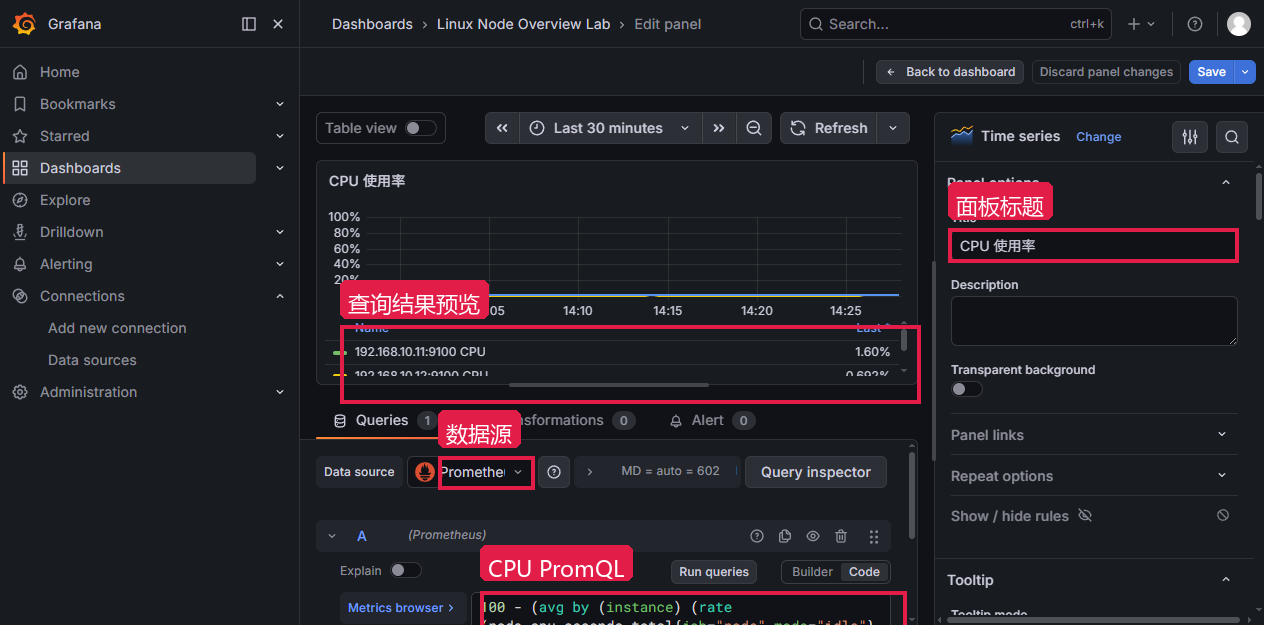
验证:编辑器上方预览区能看到三台实例的曲线,保存后回到看板仍能显示。
面板没数据时,Query inspector 可以看 Grafana 发给 Prometheus 的请求和返回错误。排查按这几个点依次过:
| 检查点 | 看什么 |
|---|---|
| Data source | 是不是选了 Prometheus |
| PromQL | 指标名、标签、聚合维度对不对 |
| 时间范围 | 是否覆盖到有数据的时间段 |
| Legend | 是否保留了定位需要的 instance/hostname |
| Unit | CPU 和内存用 Percent,流量用 bytes/sec |
CPU 面板如果一台机器出了几十条线——说明没做 avg by (instance),每个 CPU 核心各出一条线。磁盘面板出现很多奇怪挂载点——没有过滤 tmpfs 和 overlay。
看板组织
按对象拆看板比按技术拆更自然:
| 看板 | 关注内容 |
|---|---|
| Linux 主机 | CPU、内存、磁盘、网络、负载 |
| Prometheus 自身 | target 数、抓取耗时、规则计算、TSDB 状态 |
| MySQL | 连接数、QPS、慢查询、锁等待、复制 |
| Redis | 连接数、内存、命中率、淘汰、慢命令 |
| Nginx | 活跃连接、请求量、stub_status 可用性 |
| 业务服务 | 请求量、错误率、延迟、队列、下游依赖 |
主机看板能说明资源状态,但接口超时、数据库慢、缓存命中率下降这些问题,通常还要配合服务指标和日志一起来看。
常见问题
| 现象 | 常见原因 | 先看什么 |
|---|---|---|
| 数据源测试失败 | URL 写错、Grafana 到 Prometheus 不通 | 在 Grafana 机器上 curl http://127.0.0.1:9090/-/ready |
| 导入后看板空白 | DS_PROMETHEUS 没映射 | 回到导入页或 JSON 里看数据源变量 |
| Explore 有数据,面板没数据 | 面板 PromQL、变量或时间范围不对 | 打开面板编辑器看查询预览 |
| 某台机器没数据 | 对应 target 不在 UP 或标签没匹配 | up{instance="..."} 和 Targets 页面 |
| CPU 曲线太多 | 没按 instance 聚合 | avg by (instance) |
| 单位显示奇怪 | Panel unit 没设对 | Percent、bytes/sec、seconds 按指标类型选 |
Grafana 是展示层,Prometheus 才是指标来源。看板排查时把 PromQL、数据源、Prometheus Targets 和 exporter 状态放在一起看。