Appearance
Nightingale平台操作
Nightingale 的控制台操作主要围绕数据源、业务组、Dashboard、告警规则和告警事件展开。基础部署跑起来以后,真正要确认的是三件事:N9E 能查到后端时序库,Dashboard 能把采集到的主机指标展示出来,告警规则能生成可追踪的事件。
Nightingale 是监控告警平台,负责把采集器、时序库、看板、告警规则、通知策略和事件处理放到同一个控制台里。它本身不等同于时序数据库;当前实验里,指标由 Categraf 上报,数据落到 VictoriaMetrics,N9E 负责查询、展示、规则计算和事件管理。
N9E 在实验环境中作为监控平台入口,控制台能访问只说明服务已经启动,平台可用性主要看数据源接入、模板复用、规则管理、事件处理和通知链路。
一、平台操作链路
当前实验环境里,Categraf 采集主机指标,N9E 作为平台入口,VictoriaMetrics 保存时序数据,N9E 控制台再基于数据源做查询、看板和告警。
几个对象的关系如下:
| 对象 | 作用 | 平台里容易看错的点 |
|---|---|---|
| 数据源 | 告诉 N9E 到哪里查询指标 | 它不是"指标本身",只是查询和告警的后端连接 |
| 业务组 | 管理 Dashboard、规则、人员和权限归属 | 模板导入后要落到具体业务组 |
| Dashboard | 展示时序数据和表格数据 | 变量和数据源没选对时,看板会是空的 |
| 告警规则 | 定期执行查询并判断是否触发 | PromQL、数据源、级别、持续时间缺一块都容易失效 |
| 告警事件 | 规则触发后的结果记录 | 排查时主要看标签、当前值、触发时间和状态 |
业务组是 N9E 里的管理范围,同一组下面放 Dashboard、告警规则、用户权限和接收人。实验环境只有 Default Busi Group,生产里通常按业务线、环境或团队划分。
二、数据源接入
数据源回答的是"N9E 从哪里查指标"。当前实验使用 Prometheus 类型接入 VictoriaMetrics,名称为 VictoriaMetrics。这里的 Prometheus 类型指兼容 Prometheus 查询接口的数据源,N9E 可以用 PromQL 查询它;VictoriaMetrics、Mimir、Thanos 这类时序库都常按这个方式接入。
| 字段 | 当前值 | 说明 |
|---|---|---|
| 数据源类型 | Prometheus | VictoriaMetrics 兼容 Prometheus 查询协议 |
| 数据源名称 | VictoriaMetrics | Dashboard 和告警规则里会用这个名字 |
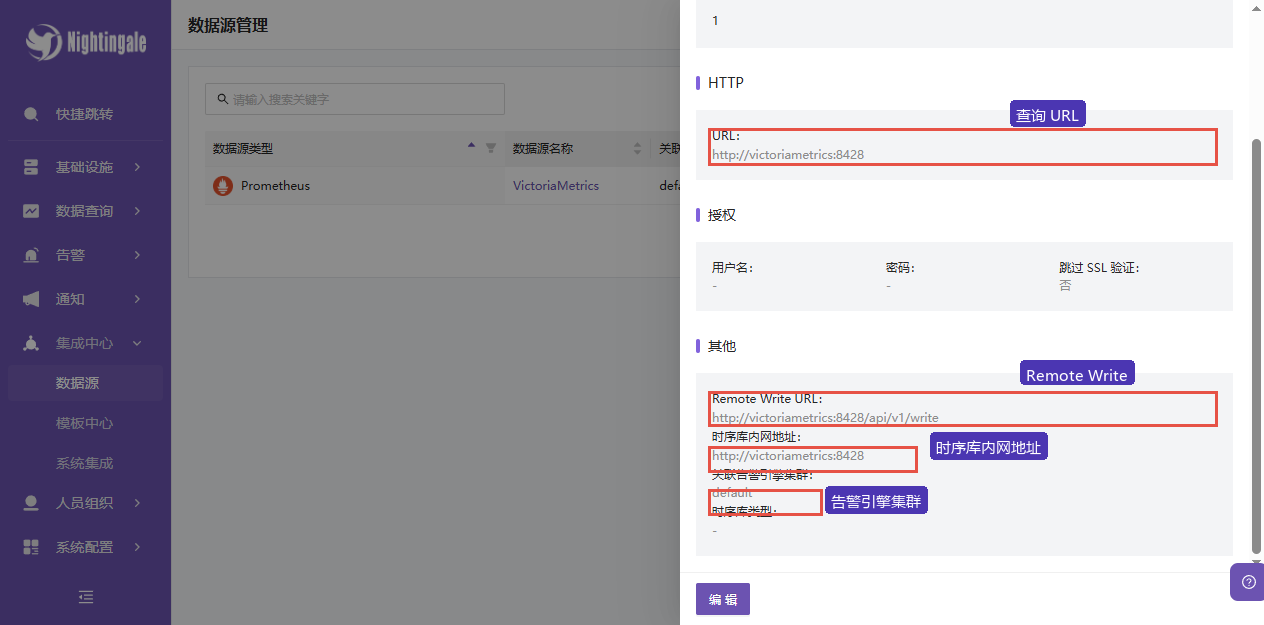
| 查询 URL | http://victoriametrics:8428 | N9E 容器访问 VictoriaMetrics 的地址 |
| Remote Write URL | http://victoriametrics:8428/api/v1/write | 指标写入地址 |
| 告警引擎集群 | default | 规则计算由这个集群里的告警引擎执行 |
控制台里的数据源入口如下:
集成中心 -> 数据源 -> 创建 / 编辑 (英文含义:Integration Center -> Data sources -> Create / Edit)
操作步骤:
- 进入
集成中心 -> 数据源,点击创建数据源;已有数据源时点击VictoriaMetrics进入详情,再点编辑。 - 数据源类型选择
Prometheus。 - 填写查询 URL、Remote Write URL 和告警引擎集群。
- 保存后回到数据源列表,确认
VictoriaMetrics出现在列表中。
字段填写:
| 字段 | 当前值 | 说明 |
|---|---|---|
| 数据源类型 | Prometheus | 表示兼容 Prometheus 查询协议 |
| 数据源名称 | VictoriaMetrics | Dashboard 和告警规则里会引用这个名字 |
| URL | http://victoriametrics:8428 | N9E 容器内访问 VictoriaMetrics 的查询地址 |
| Remote Write URL | http://victoriametrics:8428/api/v1/write | N9E 转写指标到 VictoriaMetrics 的写入地址 |
| 时序库内网地址 | http://victoriametrics:8428 | 平台内部访问时序库的地址 |
| 告警引擎集群 | default | 规则计算使用的告警引擎集群 |
保存后验证:
进入 数据查询 -> 指标 (英文含义:Data query -> Metrics),选择 VictoriaMetrics 数据源,执行 cpu_usage_active{ident="node12"}。能返回曲线或表格数据,说明 N9E 已经能查到后端时序库。
排错入口:
数据源保存失败时看页面校验提示;保存成功但查询无数据时,在 N9E 所在机器上访问 VictoriaMetrics API,再检查容器网络里的 victoriametrics:8428 是否可达。地址视角很关键,浏览器能访问 192.168.10.11:8428 不代表 N9E 容器里也能用这个地址。
数据源详情里重点看 URL、Remote Write 和告警引擎集群这几处配置。N9E 和 VictoriaMetrics 在同一个 Compose 网络里,所以地址写容器服务名 victoriametrics,不是浏览器访问用的 192.168.10.11。
后端也可以直接查一次指标,确认不是页面显示问题:
bash
# 在 VictoriaMetrics 所在机器上执行,确认 node12 已经写入主机指标
curl -sS -G \
--data-urlencode 'query=cpu_usage_active{ident="node12"}' \
http://127.0.0.1:8428/api/v1/query数据源配置最容易错在"地址视角"。浏览器能访问 192.168.10.11:8428,不代表 N9E 容器里也能用这个地址;容器内通常用服务名,物理机部署才常见 127.0.0.1 或内网 IP。
三、模板中心导入 Dashboard
模板中心里的 Dashboard 需要导入到业务组,才会出现在自己的仪表盘列表里。Linux 分类里内置了 Categraf 和 Node Exporter 两类模板,当前采集端是 Categraf,所以选择带 Categraf 标签的模板。
模板中心入口如下:
集成中心 -> 模板中心 -> Linux -> 仪表盘 (英文含义:Integration Center -> Template Center -> Linux -> Dashboard)
操作步骤:
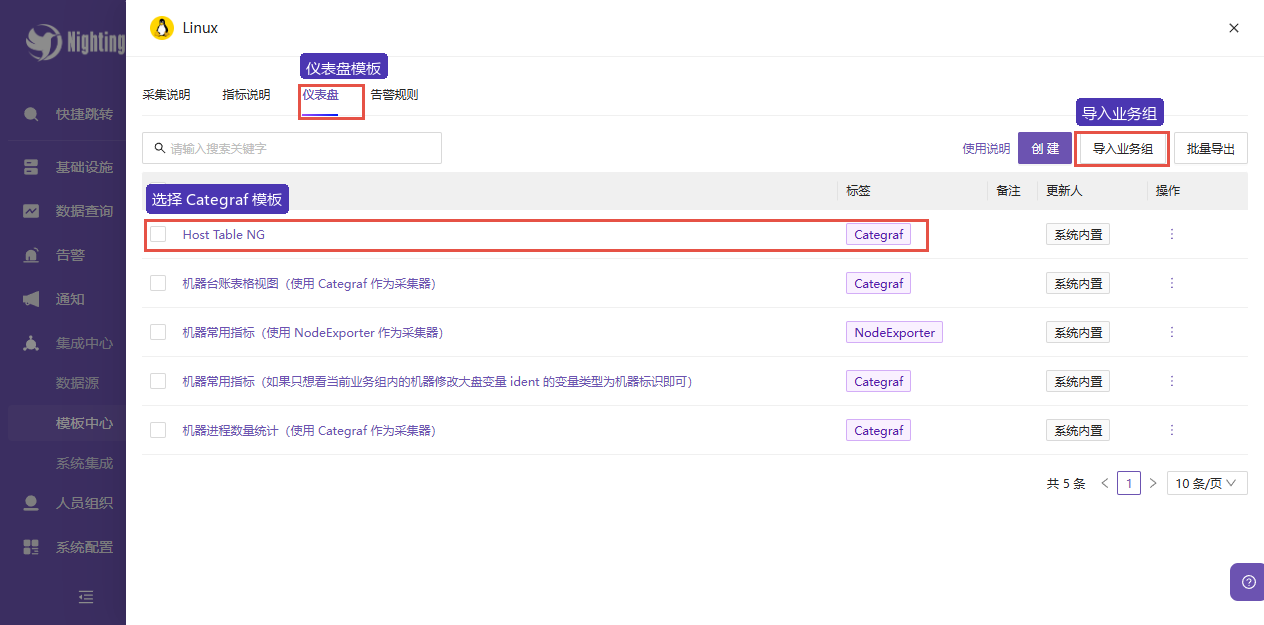
- 进入
集成中心 -> 模板中心,打开Linux分类。 - 切到
仪表盘页签。 - 勾选
Host Table NG,确认标签是Categraf。 - 点击
导入业务组。
模板选择:
| 字段 / 位置 | 当前值 | 说明 |
|---|---|---|
| 分类 | Linux | 主机监控模板所在分类 |
| 页签 | 仪表盘 | 导入 Dashboard 模板,不是告警规则模板 |
| 模板名称 | Host Table NG | 主机表格型 Dashboard |
| 标签 | Categraf | 当前实验采集端是 Categraf,所以选 Categraf 模板 |
模板列表里重点确认模板类型、Categraf 标签和"导入业务组"入口,导入失败或模板选错时可以对照这三处。
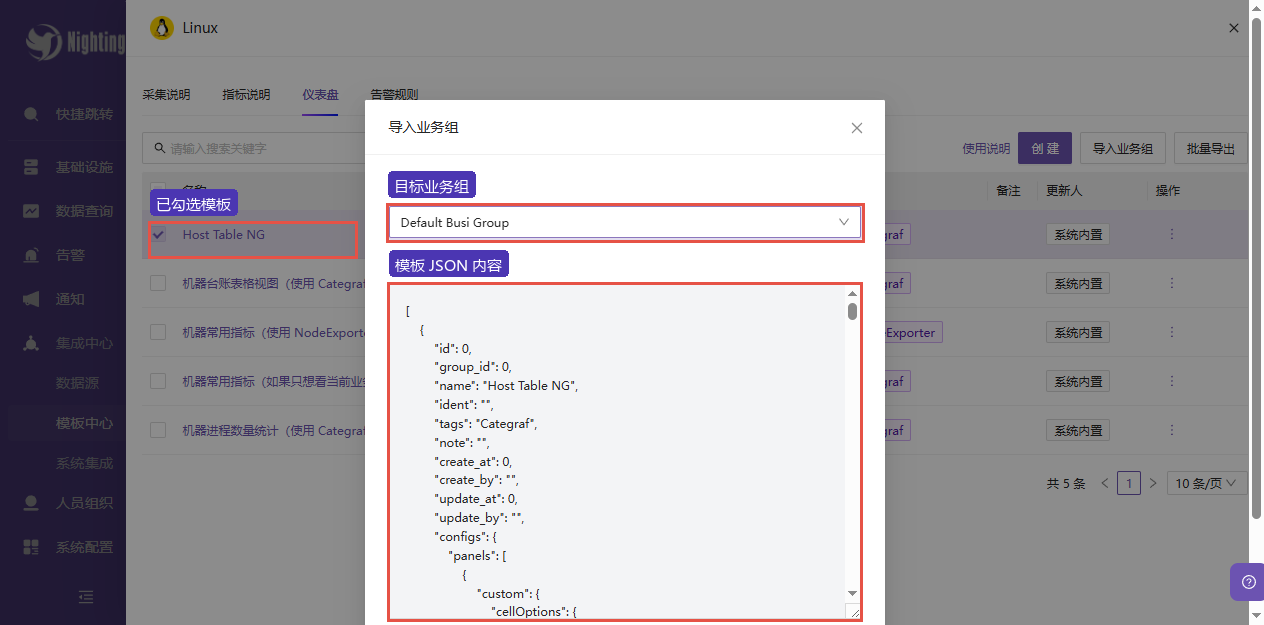
导入弹窗里选择目标业务组:
| 字段 | 当前值 | 说明 |
|---|---|---|
| 目标业务组 | Default Busi Group | Dashboard 导入后的归属业务组 |
| 模板 JSON 内容 | 保持默认 | 模板内已有变量、Panel、PromQL 和表格字段 |
操作步骤:
- 在
导入业务组弹窗里选择Default Busi Group。 - 模板 JSON 内容保持默认。
- 点击确认导入。
保存后验证:
进入 数据查询 -> 仪表盘 (英文含义:Data query -> Dashboards),列表里出现 Host Table NG,说明模板已经进入业务组。弹窗里的 JSON 是模板内容,包含变量、面板、PromQL 和表格字段等配置。平台模板导入比手动搭十几个 panel 更适合做第一版主机看板。
导入完成后,仪表盘列表里会出现 Host Table NG,分类标签是 Categraf。这一步说明模板已经变成当前业务组里的 Dashboard。
四、Dashboard 验证
打开 Dashboard 的路径如下:
数据查询 -> 仪表盘 -> Host Table NG (英文含义:Data query -> Dashboards -> Host Table NG)
操作步骤:
- 进入
数据查询 -> 仪表盘。 - 打开
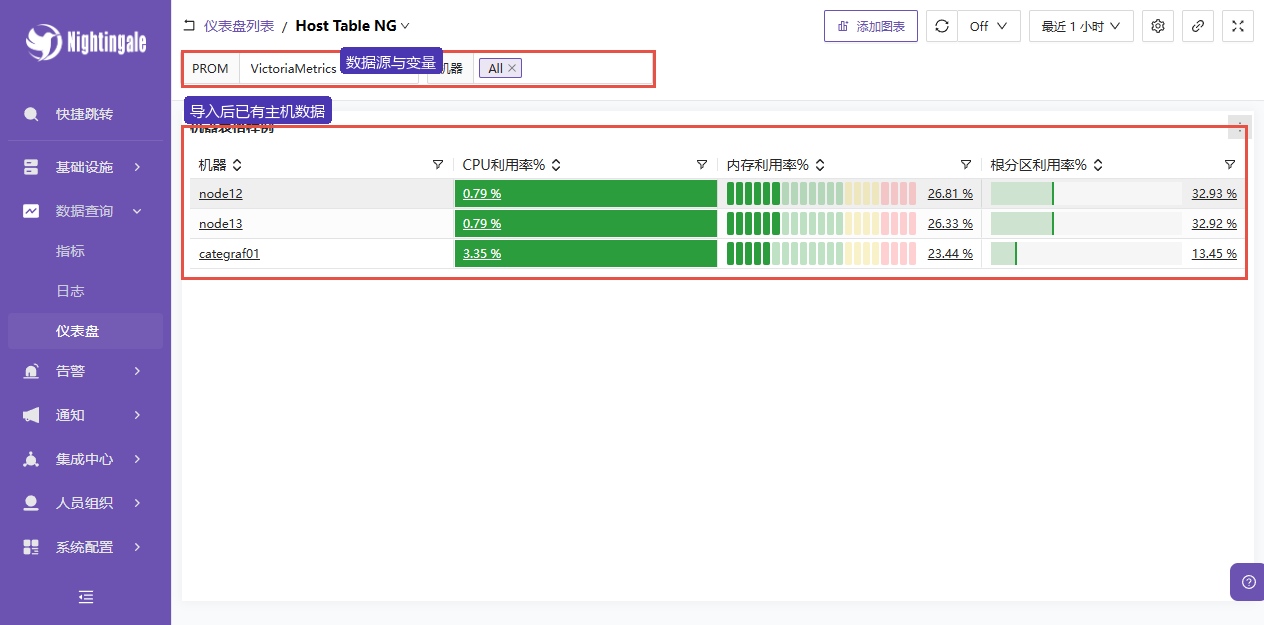
Host Table NG。 - 顶部变量
PROM选择VictoriaMetrics。 - 机器变量选择
All。 - 时间范围选择最近 1 小时。
保存后验证:
表格里能看到 node12、node13 和 categraf01,并且 CPU 利用率、内存利用率、根分区利用率都有当前值。
排错入口:
看板没有数据时,先看顶部变量 PROM 是否选中 VictoriaMetrics,再看 ident 是否为空。变量正常但表格为空时,进入 数据查询 -> 指标 执行模板里用到的 PromQL;指标查询也为空,再回到 VictoriaMetrics API 和 Categraf 日志检查上报链路。
导入后的看板要能查到真实指标:数据源选中后,主机行、CPU、内存、根分区利用率都有实际值。
Dashboard 里常见的变量:
| 变量 | 当前值 | 作用 |
|---|---|---|
PROM | VictoriaMetrics | 选择查询哪个 Prometheus Like 数据源 |
ident | All | 选择主机标识,来自指标标签 |
如果模板导入后没有数据,排查顺序通常是:数据源是否选对,时间范围是否覆盖最近数据,变量 ident 是否有值,PromQL 里用到的指标名是否和当前采集器一致。Categraf 和 Node Exporter 的指标名并不完全一样,模板选错时页面可能没有任何报错,只是没有曲线。
五、自建面板
模板能快速出图,但日常排查经常需要临时补一个面板。实验里新增一个时序图面板,标题是 主机 CPU 使用率,查询语句如下:
promql
cpu_usage_active{ident=~"$ident"}这里用 ident=~"$ident" 是为了复用 Dashboard 变量。变量选择 All 时可以看所有机器,切到单台机器时曲线会跟着收窄。通用看板里保留变量比写死主机名更灵活——写死主机名适合临时排查,不适合沉淀成共享看板。
PromQL 是 Prometheus 查询语言,这里用它从 VictoriaMetrics 取时间序列。N9E 的 Dashboard 和告警都依赖 PromQL,只是 Dashboard 把结果画成图,告警规则把结果拿去做阈值判断。
添加 Panel 的路径如下:
数据查询 -> 仪表盘 -> Host Table NG -> 添加图表 (英文含义:Data query -> Dashboards -> Host Table NG -> Add panel)
操作步骤:
- 打开
Host Table NG,点击右上角添加图表。 - 图表类型选择
时序图。 - 顶部变量
PROM选择VictoriaMetrics,机器变量保持All。 - 在 PromQL 输入框里填写
cpu_usage_active{ident=~"$ident"}。 - 右侧
面板配置里把标题填成主机 CPU 使用率。 - 左侧预览区出现曲线后,点击
保存。
字段填写:
| 字段 | 当前值 | 说明 |
|---|---|---|
| 图表类型 | 时序图 | CPU 使用率适合用时间曲线观察 |
| 数据源变量 | VictoriaMetrics | 从当前时序库查询数据 |
| PromQL | cpu_usage_active{ident=~"$ident"} | 复用 Dashboard 里的机器变量 |
| 面板标题 | 主机 CPU 使用率 | Dashboard 上显示的名称 |
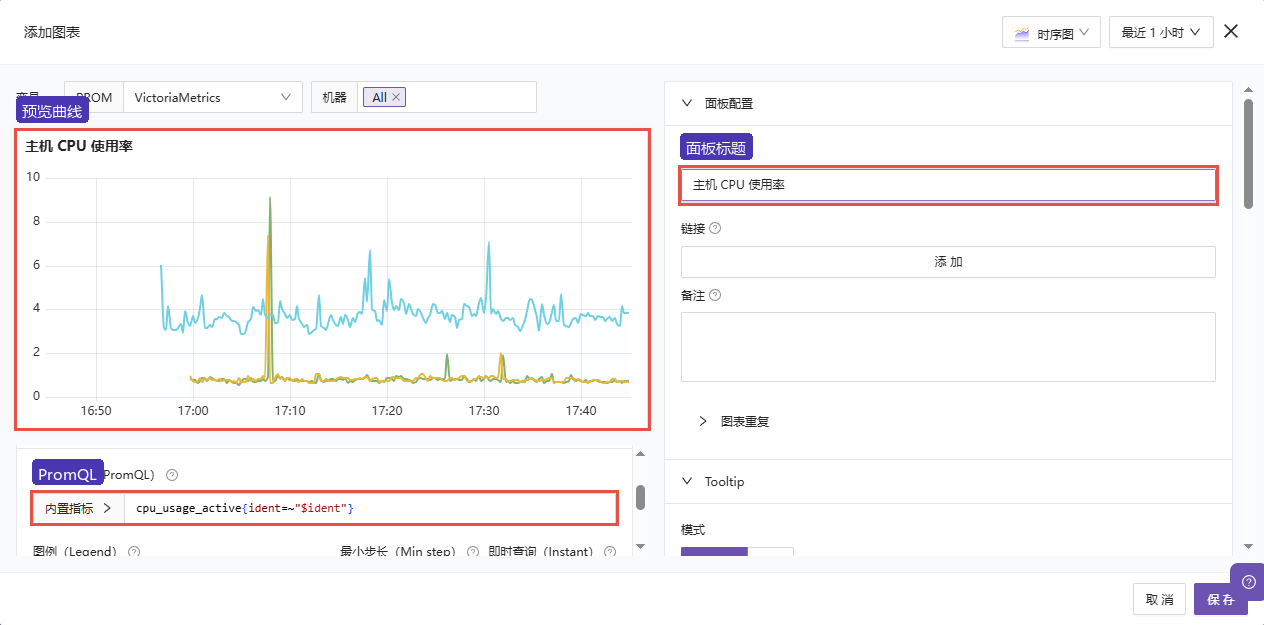
保存后验证:
保存后回到 Dashboard,新增面板能跟随 ident 变量变化。变量为 All 时显示多台机器,切到 node12 时只显示单台机器。
排错入口:
添加面板时左侧预览区没有曲线,直接在同一编辑页检查 PromQL、数据源变量和时间范围。表达式不确定时,进入 数据查询 -> 指标 用同一条 PromQL 查询。
如果只想看单台机器,可以把表达式改成:
promql
# 临时定位单台机器时使用精确匹配,避免变量展开带来干扰
cpu_usage_active{ident="node12"}主机 CPU 告警或看板里最好带上 cpu="cpu-total",否则某些采集器会同时返回每个 CPU 核心和总计值:
promql
# 只看总 CPU 使用率,避免每个核心都生成一条曲线
cpu_usage_active{cpu="cpu-total", ident="node12"}六、告警规则
N9E 的告警规则由 PromQL、数据源绑定、级别、执行频率和持续时长一起组成。PromQL 负责取数,持续时长负责过滤短暂抖动,级别和标签用于后续通知匹配。
| 字段 | 当前实验值 | 说明 |
|---|---|---|
| 规则名称 | 实验-节点CPU使用率触发 | 事件列表和通知里会显示 |
| 数据源 | VictoriaMetrics | 规则从这里查询指标 |
| PromQL | cpu_usage_active{ident="node12"} > 0 | 实验触发用,保证能生成事件 |
| 告警级别 | S2(Warning) | 当前按普通告警处理 |
| 执行频率 | @every 60s | 每 60 秒计算一次规则 |
| 持续时长 | 60 | 条件持续满足后触发 |
| 附加标签 | env=lab | 后续可用于事件过滤和通知规则 |
实验规则故意写成 > 0,目的是确认规则、告警引擎、事件链路能跑通。真实主机 CPU 告警一般写成类似下面这样:
promql
# CPU 总使用率超过 85% 才触发,避免实验阈值误用到真实环境
cpu_usage_active{cpu="cpu-total", ident="node12"} > 85告警规则入口如下:
告警 -> 规则管理 -> 创建规则 (英文含义:Alerting -> Rule management -> Create rule)
操作步骤:
- 进入
告警 -> 规则管理,点击创建规则。 - 业务组选择
Default Busi Group。 - 数据源选择
VictoriaMetrics。 - 在告警条件里填写 PromQL。
- 告警级别选择
二级告警(Warning)。 - 执行频率填写
@every 60s,持续时长填写60。 - 事件 relabel 或附加标签里保留
env=lab。 - 点击
保存。
字段填写:
| 字段 | 当前实验值 | 说明 |
|---|---|---|
| 业务组 | Default Busi Group | 规则归属 |
| 数据源 | VictoriaMetrics | 规则查询的时序库 |
| 触发表达式 | cpu_usage_active{ident="node12"} > 0 | 实验触发用表达式 |
| 告警级别 | 二级告警(Warning) | 当前按 S2 处理 |
| 执行频率 | @every 60s | 每 60 秒计算一次 |
| 持续时长 | 60 | 条件持续 60 秒后触发 |
| 标签 | env=lab | 事件过滤和通知匹配会用到 |
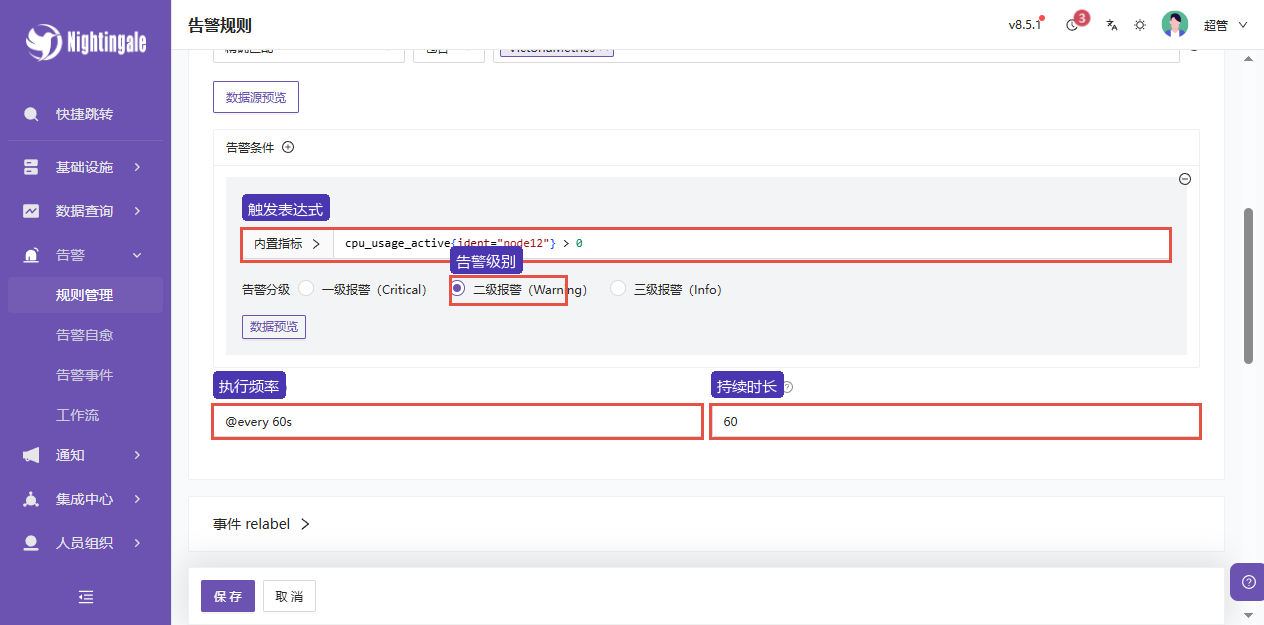
保存后验证:
规则保存后回到 告警 -> 规则管理,确认规则处于启用状态。等待一次执行周期后进入 告警 -> 告警事件,能看到规则生成的事件。
排错入口:
规则不触发时,先在规则页点击 数据预览,确认 PromQL 有结果;再检查数据源是否绑定到 VictoriaMetrics、告警引擎集群是否为 default、持续时长是否还没满足。
这里之前踩过一个坑:规则导入时如果只带 PromQL,没有绑定数据源筛选,列表里能看到规则,但告警引擎不会真正查到后端数据。N9E v8 里要确认 datasource_queries 或页面上的数据源选择已经落到规则里。现象是规则存在、启用状态正常,但 告警事件 一直没有记录。
七、告警事件
事件查看入口如下:
告警 -> 告警事件 -> 活跃告警 -> 告警详情 (英文含义:Alerting -> Alert events -> Active alerts -> Alert detail)
操作步骤:
- 进入
告警 -> 告警事件。 - 在
活跃告警列表里找到实验-节点CPU使用率触发。 - 点击事件名称或详情入口。
- 在详情弹窗里查看状态、级别、标签、触发值、PromQL 和执行频率。
验证重点:
| 字段 | 当前值 | 用途 |
|---|---|---|
| 事件状态 | Triggered | 表示规则仍在触发 |
| 告警级别 | S2(Warning) | 和规则里的级别对应 |
| 触发值 | 0.75 | 当前查询结果值 |
| 事件标签 | ident=node12、env=lab、cpu=cpu-total | 定位机器和通知匹配 |
| PromQL | cpu_usage_active{ident="node12"} > 0 | 回看触发条件 |
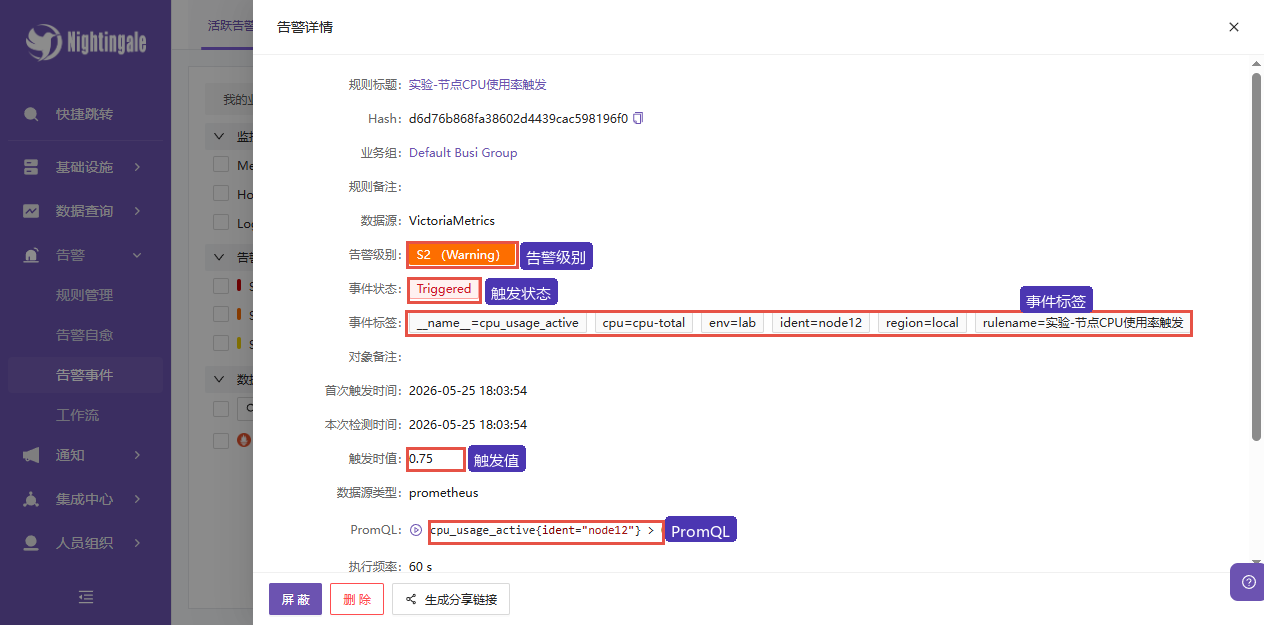
排错入口:
事件列表没有记录时,回到规则页看 数据预览 和执行周期;事件存在但通知没发时,再查 通知 -> 通知规则、通知媒介和接收组。
告警排查时,ident、env、region、__name__ 和触发值通常是第一组定位信息。只有规则名没有标签,后续排查会很慢;尤其是主机类告警,ident 基本就是定位入口。
八、通知入口
通知链路分成两层:通知媒介和通知规则。
| 对象 | 说明 |
|---|---|
| 通知媒介 | 邮件、钉钉、飞书、企业微信、Webhook 等发送通道 |
| 通知规则 | 哪些事件发给哪些接收组,是否按标签过滤 |
| 告警接收组 | 用户组或值班组,决定谁收到消息 |
| 重复通知间隔 | 告警持续未恢复时多久重复发送 |
| 恢复通知 | 告警恢复后是否发送恢复消息 |
当前实验没有接外部机器人,空的通知媒介页面不能说明通知链路可用。真正配置通知时,最少要验证一次完整链路:告警事件生成、通知规则匹配、媒介发送成功、接收端能看到机器名和触发值。
九、常见问题
| 现象 | 常见原因 | 处理方向 |
|---|---|---|
| 数据源列表正常,但查询无数据 | URL 对 N9E 容器不可达,或时间范围不对 | 在 N9E 所在机器用 curl 查 VictoriaMetrics,再回页面选数据源 |
| Dashboard 导入后是空的 | 模板采集器和实际采集器不一致 | Categraf 用 Categraf 模板,Node Exporter 用 Node Exporter 模板 |
ident 变量为空 | 指标里没有 ident 标签 | 检查 Categraf hostname、全局标签和上报数据 |
| 告警规则存在但不触发 | 数据源没绑定、PromQL 无结果、告警引擎没工作 | 查规则里的数据源筛选、PromQL 预览、告警引擎集群 |
| 有告警事件但没有通知 | 通知规则没匹配、媒介未配置、接收组为空 | 查通知规则过滤条件、通知媒介连通性、用户联系方式 |
| 告警太多 | 标签维度过细,或每个 CPU 核心都触发 | PromQL 加 cpu="cpu-total",必要时按 ident 聚合 |
N9E 平台操作是否可用,可以沿着一条事件链回看:事件里看到规则名和标签,规则里看到 PromQL 和数据源,Dashboard 里能看到同一台机器的指标,后端时序库里也能查到同一条时间序列。