Appearance
Zabbix平台操作
Zabbix 控制台操作通常沿着一条固定链路展开:主机接入、监控项定义、最近值验证、图形或 Dashboard 展示、触发器生成事件、Action 执行通知。平台页面很多,排查时关键是理清对象之间的连接关系:Host 绑定哪个 Interface,Item 的 key 从哪里来,Latest data 有没有真实值,Trigger 表达式命中后 Action 有没有留下发送记录。
当前实验环境:
| 角色 | 地址 | 说明 |
|---|---|---|
| Zabbix Server / Web / DB | 192.168.10.11 | Server、Web、MariaDB、Agent2 |
| 被监控节点 | 192.168.10.12 | Linux Agent2 |
| 被监控节点 | 192.168.10.13 | Linux Agent2,自定义指标实验节点 |
一、对象关系
Zabbix 里的平台对象有层级关系。Host 是被监控对象,Interface 是采集入口,Item 是具体采什么数据,Trigger 是把数据变成问题事件的规则,Action 是事件发生后要执行的通知或脚本动作。
对象之间的关系直接影响排错顺序。Agent 命令能返回值,只说明被监控机本地或 Server 到 Agent 的链路通了;Latest data 出现最近值,才说明 Zabbix 的 Item 已经把数据收进平台;Trigger 生成 Problem,才说明告警规则真的参与了事件处理。
二、主机接入
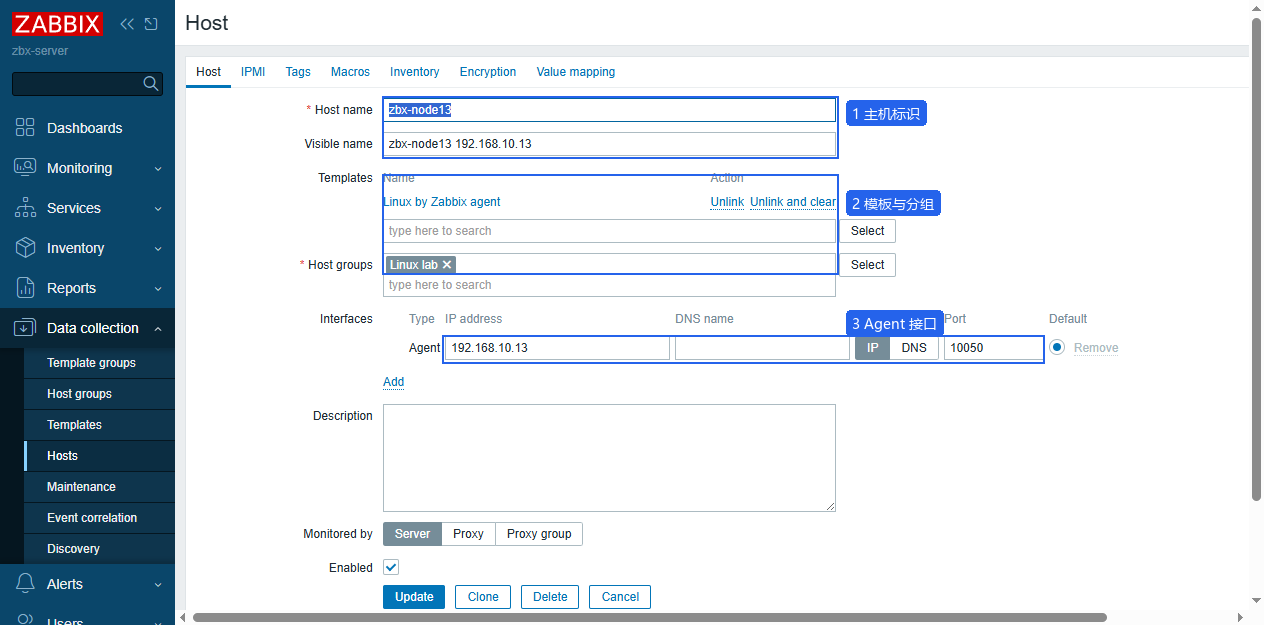
Linux Agent 被接入平台时,主机页最关键的是 Host name、Host groups、Templates 和 Agent interface。Host name 是平台内部识别名,主动模式下还会和 Agent 配置里的 Hostname= 对齐;Visible name 只是展示名,通常会带 IP,方便在列表和告警里辨认。
操作路径:
Data collection -> Hosts -> Create host (中文:数据采集 -> 主机 -> 创建主机)
操作步骤:
- 进入
Data collection -> Hosts,点击右上角Create host。 - 在
Host页填写Host name、Visible name和Host groups。 - 在
Interfaces区域添加Agent接口,填写被监控机 IP 和端口。 - 在
Templates区域选择Linux by Zabbix agent。 - 点击
Add保存主机。
| 字段 | 当前值 | 作用 |
|---|---|---|
| Host name | zbx-node13 | 平台内部主机名 |
| Visible name | zbx-node13 192.168.10.13 | 页面展示名 |
| Host groups | Linux lab | 分组、权限、筛选和 Action 条件都可能用到 |
| Templates | Linux by Zabbix agent | 模板提供 Linux 基础监控项和触发器 |
| Agent interface | 192.168.10.13:10050 | Server 访问 Agent 的入口 |
保存后验证:
Data collection -> Hosts (中文:数据采集 -> 主机)
主机列表里 zbx-node13 的 ZBX 状态变绿,表示 Zabbix Server 能通过 Agent 接口通信。更直接的验证方式是进入 Monitoring -> Latest data(中文:监控 -> 最新数据)筛选 zbx-node13,确认模板 Item 已经有最近值。
排错入口:
Data collection -> Hosts -> zbx-node13 -> Interfaces (中文:数据采集 -> 主机 -> zbx-node13 -> 接口)
这里检查 IP、端口和接口类型。页面仍不绿时,在 Server 上用 zabbix_get 验证 10050 端口和 Agent key;Agent 日志里再看 Server=、Hostname=、防火墙和 SELinux 相关问题。
Server 侧可以直接用 zabbix_get 验证 Agent 链路。这个命令绕过 Web 页面过滤条件,适合确认"Server 到 Agent 是否真的能取值"。
bash
# 在 Zabbix Server 上执行,确认 192.168.10.13 的 Agent 有响应
zabbix_get -s 192.168.10.13 -k agent.ping
# 查看 Agent 返回的主机名,主动模式排错时经常会用到
zabbix_get -s 192.168.10.13 -k system.hostname当前返回值:
text
1
zbx-node13agent.ping=1 表示 Agent 通信正常。这个结果还不能代表业务指标正常,只能说明 Agent 入口可用。
三、自定义指标
模板能覆盖 CPU、内存、磁盘、进程等常见指标,但业务健康状态、脚本检查结果、特殊端口状态通常需要自定义 Item。Zabbix Agent2 侧可以通过 UserParameter 暴露自定义 key,Server 再用 Item 去采集这个 key。
zbx-node13 上的实验配置:
ini
# /etc/zabbix/zabbix_agent2.d/lab-userparameter.conf
# 当前系统进程数量,用于演示普通数值型自定义指标
UserParameter=lab.proc.count,ps -e --no-headers | wc -l
# 用文件模拟应用健康状态:1 表示正常,0 表示异常
UserParameter=lab.app.health,cat /tmp/lab_app_health 2>/dev/null || echo 1修改 Agent 配置后重启服务:
bash
# 初始化健康状态文件,避免第一次采集返回空值
printf '1\n' >/tmp/lab_app_health
# 重新加载 Agent2 配置文件
systemctl restart zabbix-agent2
# 确认 Agent2 正常运行,10050 端口处于监听状态
systemctl is-active zabbix-agent2
ss -lntp | grep ':10050\b'Server 侧直接验证自定义 key:
bash
# 直接读取进程数量,返回值应为一个整数
zabbix_get -s 192.168.10.13 -k lab.proc.count
# 直接读取应用健康状态,正常状态返回 1
zabbix_get -s 192.168.10.13 -k lab.app.health当前返回值类似:
text
187
1平台侧创建 Item 时,字段要和 Agent key 对齐:
操作路径:
Data collection -> Hosts -> zbx-node13 -> Items -> Create item (中文:数据采集 -> 主机 -> zbx-node13 -> 监控项 -> 创建监控项)
操作步骤:
- 进入
Data collection -> Hosts,点击zbx-node13。 - 打开
Items,点击Create item。 - 创建
Lab process count,Key填lab.proc.count。 - 再创建
Lab application health,Key填lab.app.health。 - 两个 Item 都选择
Zabbix agent类型,信息类型选择Numeric (unsigned)。 - 点击
Add保存。
| 字段 | Lab process count | Lab application health | 说明 |
|---|---|---|---|
| Type | Zabbix agent | Zabbix agent | Server 通过 Agent 被动采集 |
| Key | lab.proc.count | lab.app.health | 和 UserParameter 的 key 保持一致 |
| Type of information | Numeric (unsigned) | Numeric (unsigned) | 两个值都是整数 |
| Update interval | 30s | 30s | 实验环境方便观察,生产环境按指标重要程度设置 |
| History | 7d | 7d | 原始值保留时间 |
| Trends | 30d | 30d | 趋势数据保留时间 |
| Tags | scope=lab, component=custom | scope=lab, component=custom | 方便筛选 Latest data、事件和 Action |
保存后验证:
Monitoring -> Latest data (中文:监控 -> 最新数据)
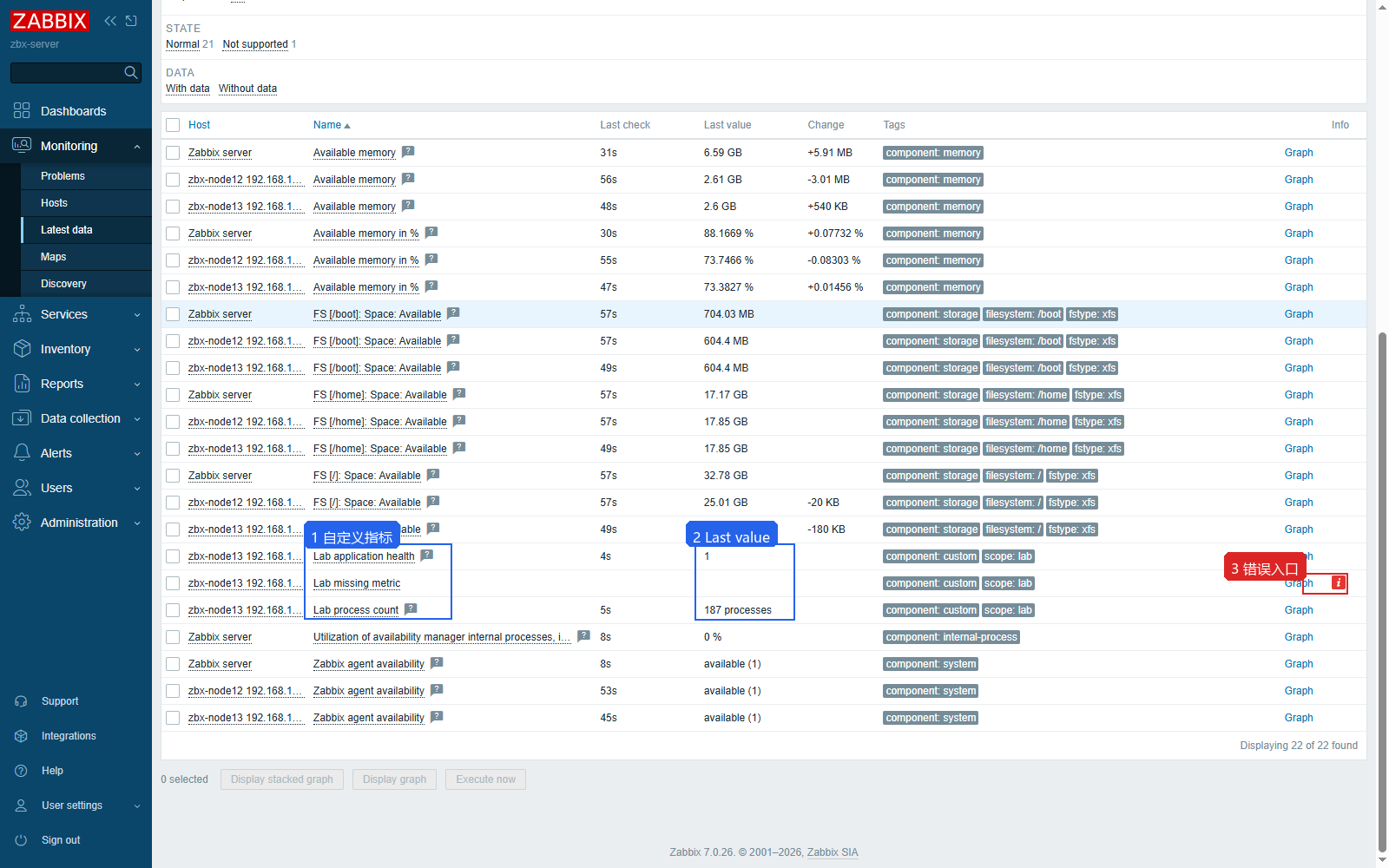
筛选 Host groups=Linux lab、Hosts=zbx-node13,在 Name 里搜索 Lab。Lab process count 和 Lab application health 有 Last check 与 Last value,说明自定义 Item 已经进入平台采集链路。
Item 创建完以后,Latest data 是最直接的验证页面。图里能看到两个自定义指标已经有最近值,同时故意创建的 Lab missing metric 处于异常入口,适合记录自定义指标排错位置。
Latest data 的几个字段含义:
| 字段 | 说明 |
|---|---|
| Host | 数据来自哪台主机 |
| Name | Item 展示名 |
| Last check | 最近一次采集距离当前的时间 |
| Last value | 最近一次采集到的值 |
| Tags | Item 标签,告警路由和筛选都会用到 |
| Info | Item 异常原因入口,Not supported 时尤其重要 |
排错入口:
Data collection -> Hosts -> zbx-node13 -> Items (中文:数据采集 -> 主机 -> zbx-node13 -> 监控项)
Item 变成 Not supported 时看 Info 列。Unknown metric 通常说明 Agent 侧没有加载对应 UserParameter;权限错误、脚本超时、返回值类型不匹配,也会在这里暴露。
Lab missing metric 的错误原因是 Unknown metric lab.missing.metric。这种错误一般不是 Web 页面问题,而是 Agent 侧没有这个 key,或者 UserParameter 文件没有加载。修复顺序可以按下面走:
bash
# 在 Server 侧直接验证错误 key,确认 Agent 是否认识这个指标
zabbix_get -s 192.168.10.13 -k lab.missing.metric
# 在 Agent 节点确认自定义配置文件是否存在
grep -R 'lab.missing.metric' /etc/zabbix/zabbix_agent2.d/ /etc/zabbix/zabbix_agent2.conf
# 修改 UserParameter 后重启 Agent2,再回到 Latest data 等待下一轮采集
systemctl restart zabbix-agent2四、图形与Dashboard
Latest data 能证明数据已经进平台,但日常值班更依赖图形和 Dashboard。图形关注趋势,Dashboard 把多个对象放到同一张视图里。当前实验 Dashboard 放了三块内容:进程数量趋势、应用健康值、当前问题列表。
图形创建路径:
Data collection -> Hosts -> zbx-node13 -> Graphs -> Create graph (中文:数据采集 -> 主机 -> zbx-node13 -> 图形 -> 创建图形)
操作步骤:
- 进入
zbx-node13的Graphs页面,点击Create graph。 Name填Lab process count trend。- 在 Items 里添加
Lab process count。 - 点击
Add保存。
Dashboard 配置路径:
Dashboards -> Create dashboard / Edit dashboard -> Add widget (中文:仪表盘 -> 创建/编辑仪表盘 -> 添加组件)
字段填写:
| 组件 | 类型 | 关键配置 |
|---|---|---|
Lab process count trend | Graph | 选择 Graph Lab process count trend |
Lab application health | Item value | Host 选 zbx-node13,Item 选 Lab application health |
Lab problems | Problems | 过滤 scope=lab 或当前主机相关问题 |
保存后验证:
打开对应 Dashboard,进程数量有趋势线,应用健康值显示 1.00,Problems 组件能在触发器命中后显示事件。Dashboard 没图时回 Monitoring -> Latest data 确认 Item 先有值,再检查 Graph 或 Widget 绑定的 Item 是否正确。
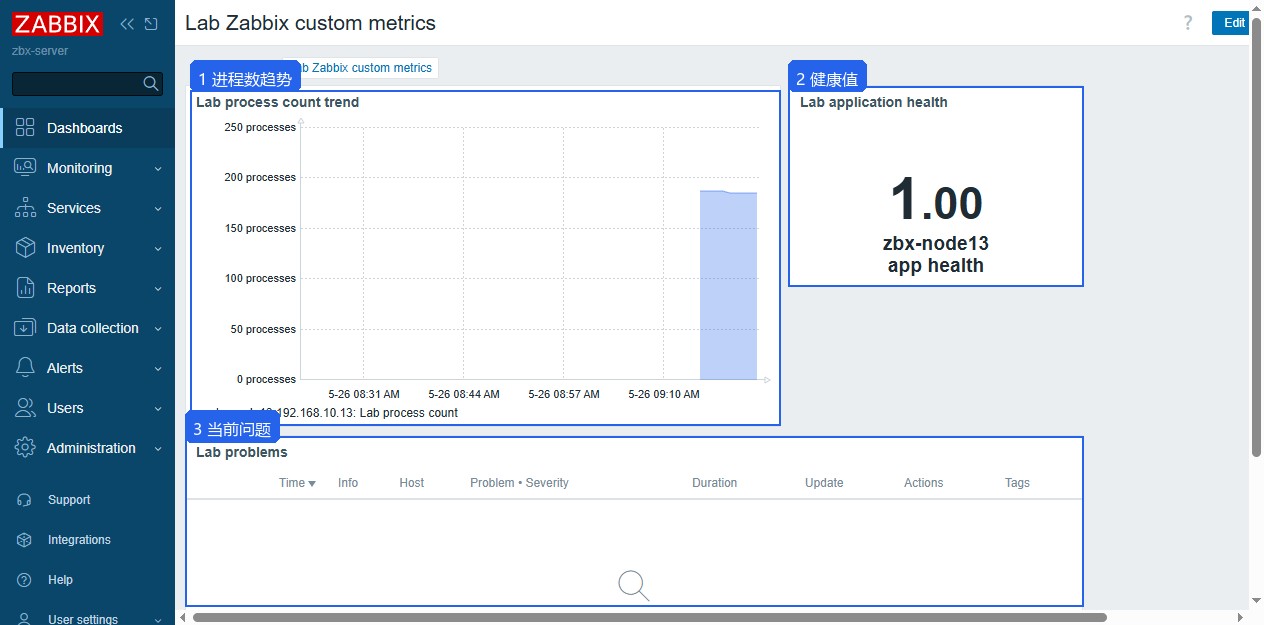
Dashboard 里这三个组件对应的关系:
| 组件 | 数据来源 | 用途 |
|---|---|---|
Lab process count trend | Graph Lab process count trend | 看进程数量是否突然上涨或下降 |
Lab application health | Item Lab application health | 直接展示当前健康值 |
Lab problems | Problems widget | 查看当前未恢复的问题 |
进程数量这种指标适合用趋势图。健康状态这种 0/1 指标适合用单值面板,值为 1 时表示正常,值为 0 时表示异常。Dashboard 里如果只放默认模板图,后续排查自定义指标时还要回 Latest data 重新筛选;把实验指标单独放出来,能直接看到它是否还在采集。
五、触发器
Trigger 用来把 Item 的值转换成问题事件。当前实验的触发器为:
text
last(/zbx-node13/lab.app.health)=0表达式含义是:zbx-node13 这台主机的 lab.app.health 最近一次值等于 0 时,触发问题。这个表达式适合演示业务健康状态,不依赖停止 Agent 服务,所以能区分"Agent 掉线"和"应用状态异常"。
操作路径:
Data collection -> Hosts -> zbx-node13 -> Triggers -> Create trigger (中文:数据采集 -> 主机 -> zbx-node13 -> 触发器 -> 创建触发器)
操作步骤:
- 进入
zbx-node13的Triggers页面,点击Create trigger。 Name填Lab application health is down。Expression填last(/zbx-node13/lab.app.health)=0。Severity选择High。- 添加标签
scope=lab、component=app、node=zbx-node13。 - 点击
Add保存。
保存后验证:
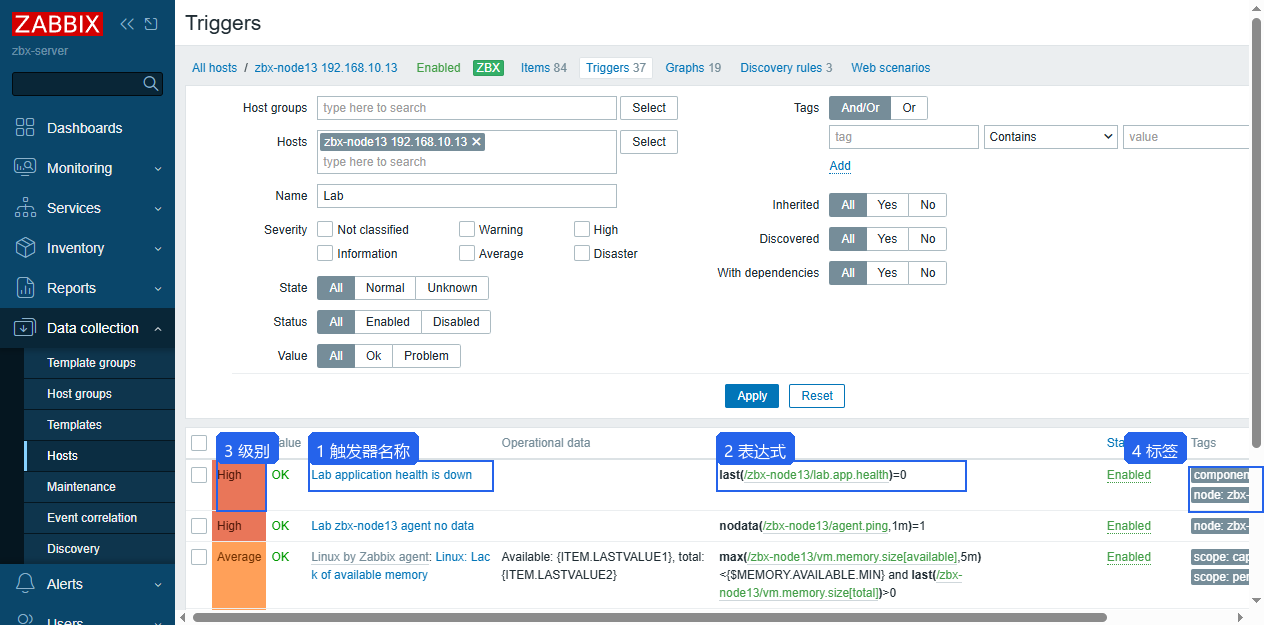
Data collection -> Hosts -> zbx-node13 -> Triggers (中文:数据采集 -> 主机 -> zbx-node13 -> 触发器)
列表里能看到触发器名称、表达式、严重级别和标签。后续把 lab.app.health 改为 0 时,Monitoring -> Problems(中文:监控 -> 问题)会生成事件。
字段含义:
| 字段 | 当前值 | 说明 |
|---|---|---|
| Name | Lab application health is down | 问题名会出现在 Problems 和通知里 |
| Expression | last(/zbx-node13/lab.app.health)=0 | 最近值为 0 时触发 |
| Severity | High | 告警级别,用于过滤和通知策略 |
| Tags | scope=lab, component=app, node=zbx-node13 | Action 匹配和事件筛选都会用到 |
| Manual close | enabled | 实验里允许手动关闭问题 |
排错入口:
触发器不出事件时,先看 Monitoring -> Latest data 里的 Lab application health 最近值,再回触发器表达式确认 Host、Item key、函数和比较值。值类型不匹配、Item 没数据、表达式 host 名写错,都会导致规则看似存在但不触发。
last() 只看最近一次值。实际生产里还会遇到抖动问题,比如健康检查偶发返回 0,下一次又恢复。类似场景通常会加持续时间或次数判断,例如用 min(/host/key,3m)=0 表示 3 分钟内最小值都是 0,告警会更稳。
六、制造一次事件
lab.app.health 的值由 /tmp/lab_app_health 控制。把文件写成 0,Agent 下一次读取时就会返回异常值;恢复成 1 后,触发器会生成恢复事件。
bash
# 在 zbx-node13 上执行,模拟应用健康检查失败
printf '0\n' >/tmp/lab_app_health
# 从 Server 侧确认 Agent 已经返回异常值
zabbix_get -s 192.168.10.13 -k lab.app.health恢复:
bash
# 在 zbx-node13 上执行,恢复应用健康状态
printf '1\n' >/tmp/lab_app_health
# 从 Server 侧确认健康值已经恢复
zabbix_get -s 192.168.10.13 -k lab.app.healthProblems 页面记录了这次事件。图里能看到发生时间、恢复时间、状态、问题名、持续时间和 Action 次数。RESOLVED 表示触发器已经从 Problem 状态恢复。
查看路径:
Monitoring -> Problems (中文:监控 -> 问题)
操作步骤:
- 进入
Monitoring -> Problems。 - 筛选主机
zbx-node13,或按标签scope=lab过滤。 - 查看
Lab application health is down的状态、发生时间、恢复时间和 Action 次数。 - 点击问题名称或事件详情,查看事件标签和恢复记录。
验证重点:
| 字段 | 作用 |
|---|---|
| Time | 问题发生时间 |
| Recovery time | 恢复时间 |
| Status | 当前状态,常见为 PROBLEM 或 RESOLVED |
| Host | 影响对象 |
| Problem | 触发器名称 |
| Duration | 持续时间 |
| Actions | 事件关联的通知或动作次数 |
| Tags | Action 匹配和后续筛选依据 |
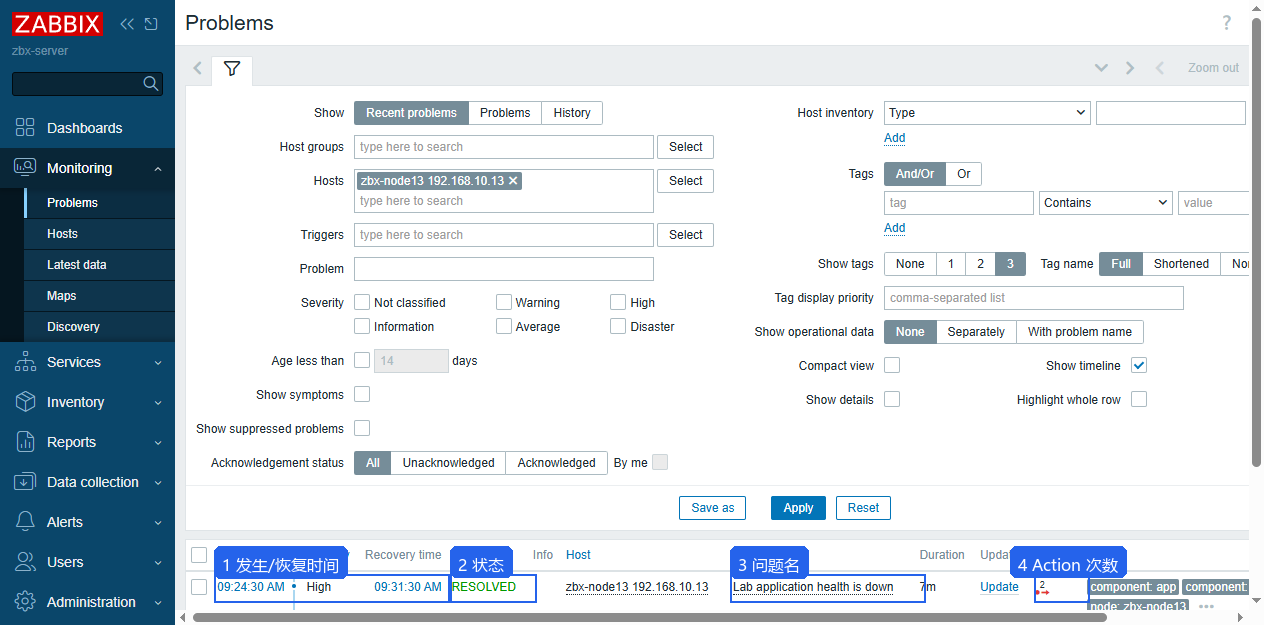
同一台主机上 Agent 掉线和业务健康失败是两类问题。Agent 掉线通常表现为 agent.ping、agent.available 异常;业务健康失败则是自定义 key 返回异常值。复盘时把这两类写开,定位会更清楚。
七、Action与通知记录
Action 负责把事件转成通知动作。它不是触发器本身,而是事件匹配规则。一个 Action 通常由 Conditions、Operations、Recovery operations 组成。
操作路径:
Alerts -> Actions -> Trigger actions -> Create action (中文:告警 -> 动作 -> 触发器动作 -> 创建动作)
操作步骤:
- 进入
Alerts -> Actions -> Trigger actions,点击Create action。 Name填Lab app health action。Conditions里添加条件,匹配触发器Lab application health is down。Operations里添加发送消息给Admin,媒介选择Lab script notification。Recovery operations里也添加发送消息给Admin。- 点击
Add保存。
保存后验证:
Alerts -> Actions -> Trigger actions (中文:告警 -> 动作 -> 触发器动作)
列表里确认 Action 处于启用状态,条件、Operation 和 Recovery operation 都存在。再制造一次 lab.app.health=0 的事件,Action 次数会出现在 Problems 页面。
Action 字段关系:
| 对象 | 当前值 | 说明 |
|---|---|---|
| Action | Lab app health action | 告警动作名称 |
| Condition | Trigger equals Lab application health is down | 只匹配这个实验触发器 |
| Operation | Send message to Admin | 问题发生时发送 |
| Recovery operation | Send message to Admin | 问题恢复时发送 |
| Media type | Lab script notification | 实验用脚本媒介 |
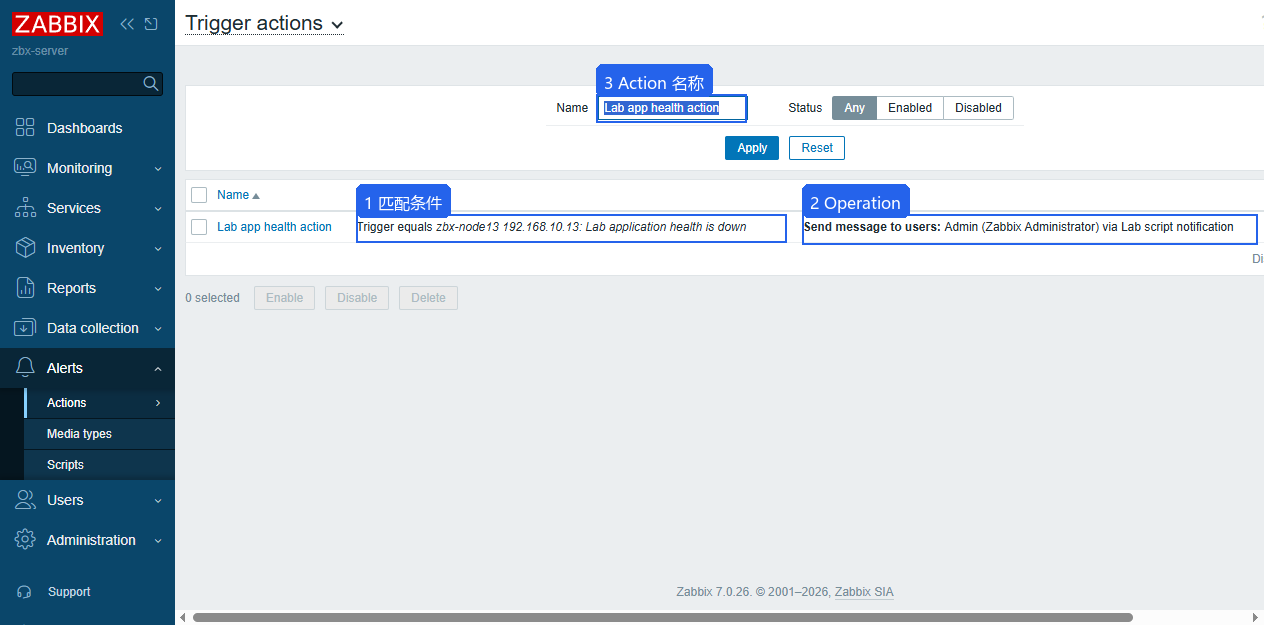
Action 配好以后,还要看 Action log。事件出现但没有通知到人时,Action log 比 Action 列表更关键,因为它会说明有没有匹配到 Action、用了哪个媒介、发给谁、状态是什么。
查看路径:
Reports -> Action log (中文:报表 -> 动作日志)
操作步骤:
- 进入
Reports -> Action log。 - 按时间范围筛选刚才制造的事件。
- 查看
Action、Media type、Recipient、Status和Info。 Status=Failed时点击或展开Info,查看失败原因。
排错入口:
Problems 有事件但 Action log 没记录,通常是 Action 条件没匹配、Action 未启用,或 Operation 没配置。Action log 有记录但失败,就看 Info 里的媒介、消息模板、用户 Media、脚本权限或外部通知接口错误。
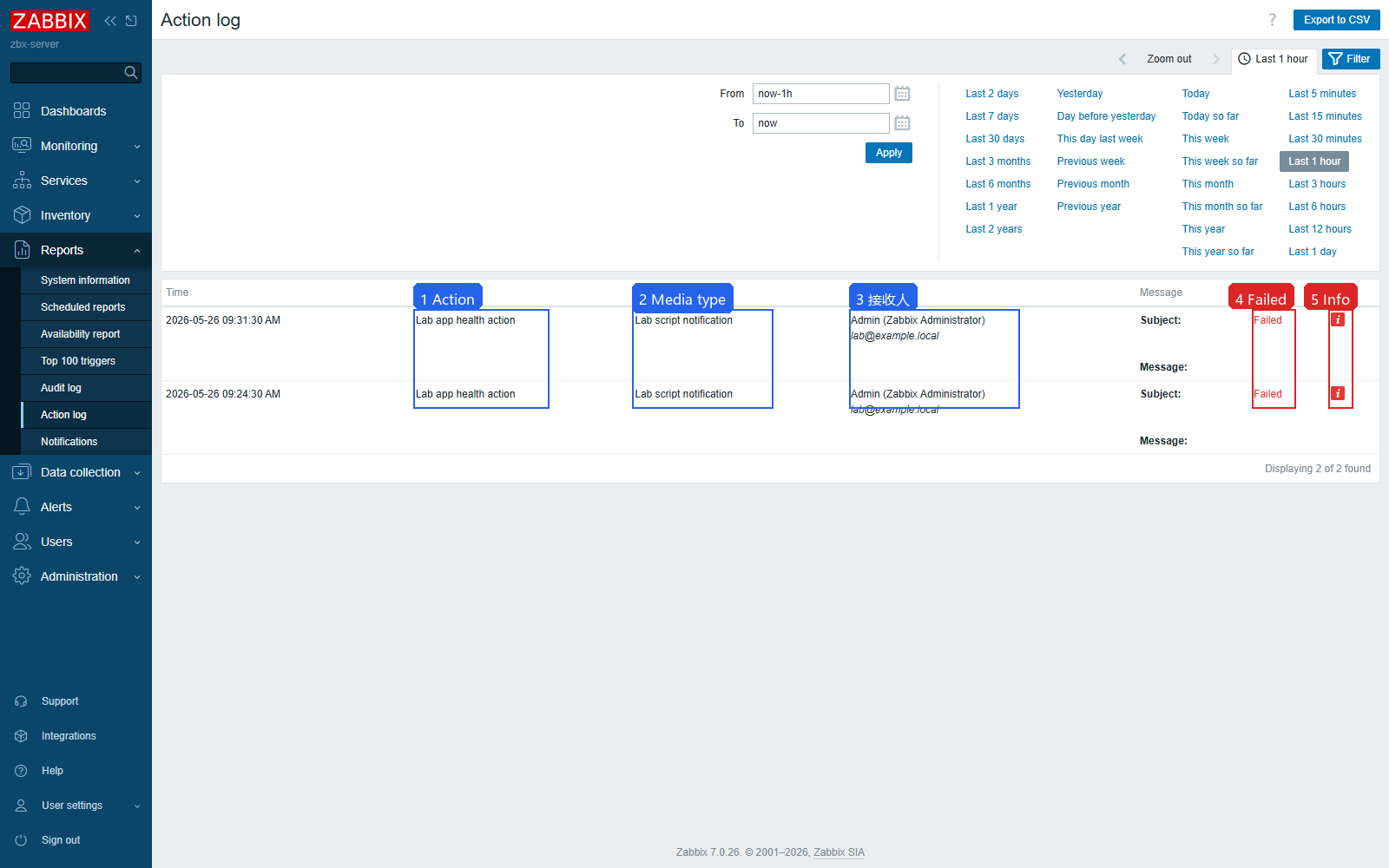
当前实验里 Action log 有两条记录:一条对应问题发生,一条对应恢复。两条记录都显示 Failed,错误文本为:
text
No message defined for media type.这说明 Action 条件已经匹配,通知动作也被创建了,但媒介或消息模板没有配置完整。故障现场遇到"Problems 有事件但没收到通知"时,可以按下面顺序查:
- Problems 页面是否真的生成事件。
- 事件标签、级别、主机组是否符合 Action 条件。
- Action 是否 Enabled。
- Operation 和 Recovery operation 是否都配置了接收人。
- 用户是否绑定了可用 Media。
- Media type 是否启用,消息内容或脚本参数是否完整。
- Action log 里是否有 Failed 和具体错误原因。
八、常见断点
Zabbix 平台操作排错时,经常不是一个页面能看完。比较稳的检查路径如下:
| 现象 | 优先位置 | 常见原因 | 修复方向 |
|---|---|---|---|
主机 ZBX 不绿 | Hosts / zabbix_get | Agent 未启动、10050 不通、Server= 不允许 | 启动 Agent、放通防火墙、修正 Agent 配置 |
| Latest data 没值 | Latest data / Items | 没绑定模板、Item disabled、更新间隔未到 | 绑定模板、启用 Item、等待或 Execute now |
| 自定义 key Not supported | Latest data / Item Info | UserParameter 不存在、配置文件未加载、脚本无权限 | 修正 Agent 配置、重启 Agent、用 zabbix_get 验证 |
| Dashboard 没图 | Dashboard / Graph | Item 没数据、图形绑定错 Item、时间范围不对 | 回 Latest data 确认值,再检查 Graph 或 Widget |
| Trigger 不出事件 | Triggers / Problems | 表达式写错、值类型不匹配、条件没有达到 | 看 Latest value,再对照表达式函数 |
| 有事件没通知 | Action log | Action 条件不匹配、用户 Media 缺失、Media type 配置错误 | 查 Action 条件、用户媒介、Action log 错误 |
平台上能看到红色状态时,信息还不够完整。还要补上错误原因:Item 的 Info、Problem 的详情、Action log 的 Failed 原因、Server 和 Agent 日志。Zabbix 的页面层级比较多,排错时把"配置对象、数据结果、错误入口"三类证据放在一起,后续复盘才不会只剩一个红色状态截图。